第 5 章 Programming
5.1 Function
將programming block {….} 存成可反覆再使用的一種物件。
5.1.1 範例:Present Discounted Value
Given nominal interest rate 9% per year, what is $10,000 worth three year from now in terms of today’s money (i.e. present discounted value of $10,000)?
\[ 10000/(1+0.09)^3\] Block programming
# Given some information
R <- 0.09
M <- 10000
T <- 3
# What I need to do
PDV <-
{
M/(1+R)**T
}Function
getPDV <- function(R,M,T)
{
M/(1+R)**T
}
getPDV(R=0.09, T=3, M=10000)5.1.2 Execution Environment
執行getPDV(R=0.09, T=3, M=10000)時,Global Environment並不需要有R, T, M,執行完函數呼叫後也不會在Global environment產生R, T, M物件,那是因為它會有另外的執行環境(executive environment)在記錄這些物件及{…}計算過程中的任何新生物件。
debug(getPDV)
getPDV(R=0.09, T=3, M=10000)
undebug(getPDV)- An execution environment is usually ephemeral; once the function has completed, the environment will be garbage collected.
5.1.3 Function components
# 查詢函數formals arguments要求
formals(getPDV)$R
$M
$T
# 查詢函數主體
body(getPDV){ M/(1 + R)^T }
# body執行時若有物件不存在execution environment時要去找尋的environment
environment(getPDV)<environment: R_GlobalEnv>
- the environment is specified implicitly, based on where you defined the function, also called function environment.
5.1.4 Function Environment
When function body {…} needs an object value but the object does not exist inside the execution environment, it will look for it at the function environment first. In other words, function execution will look for required information at its birth place first if the information is not inside the execution environment.
# Given some information
T <- 3
# What I need to do
getPDV2 <- function(R,M){
M/(1+R)**T
}getPDV2(R=0.12, M=50000)
debug(getPDV2)
getPDV2(R=0.12, M=50000)
undebug(getPDV2)
由於函數執行時遇到exec. environment沒有的物件,假設叫globeX, 會去它的function environment找,這表示相同的執行設定,在不同時間執行時,若globeX已更動,它們的執行結果不會相同。
T <- 3
getPDV2(R=0.12, M=50000)T <- 1
getPDV2(R=0.12, M=50000)Though function execution will look for objects in the functional environment (named FE) when they are not found inside the execution environment (named EE), replacement operation on a EE-missing object will not replace its FE-counterpart.
globalX <- c(2,5)
testfun <- function(){
globalX[[2]] <- -1
invisible(3+globalX)
}
testfun()
globalXdebug(testfun)
testfun()
undebug(testfun)- Replacement on a FE-counterpart implicitly creates a EE local object with the same object name.
5.1.5 Return
函數由execution environment輸出的值, 可以是:
- 最後一個執行列的運算值(值不能儲存在任何物件):
testFun <- function(){
a <-2
b <- 5
a+b
}
testFun()testErrorFun <- function(){
a <-2
b <- 5
output <- a+b
}
testErrorFun()- 執行列出現
return()時,()內的值會回傳:
testFun <- function(){
a <-2
b <- 5
return(a+b)
}
testFun()- 執行列出現
invisible()時,()內的值只在函數呼叫同時有指定物件儲存時才會回傳:
testFun <- function(){
a <-2
b <- 5
invisible(a+b)
}
testFun()
output <- testFun()
output5.1.6 Function as value
- Function can be saved in a list
demandFun <- function(P) 5-3*P
supplyFun <- function(P) 1+0.5*P
market <- list(
demand=demandFun,
supply=supplyFun
)- Function can be used as an function argument
Derivative \(f'(x)\) of a function \(f(x)\) is defined as: \[f'(x_0) = \lim_{\epsilon \rightarrow 0}\ \frac{f(x_0+\epsilon)-f(x_0)}{\epsilon}\] Suppose we want to construct a function that can compute \(f'(0)\) for any function.
df0 <- function(f){
epsilon <- 0.00001
(f(epsilon)-f(0))/epsilon
}
df0(market$demand)
df0(market$supply)5.1.7 Applications
星座查詢
library(lubridate); library(dplyr); library(stringr); library(purrr)
jsonlite::fromJSON(
"https://www.dropbox.com/s/8sftw4bbjumeqph/signMapping.json?dl=1") -> horoscopesStep1: Block programming
userBirthday <-
userHoroscopes <-
{
}Block programming in details (pseudo-codes):
userBirthday <- ymd("1998-10-30")
userHoroscopes <-
{
# 取得生日年份
birthYear <- {
}
# 取得生日年份的12星座起始日期
horoscopeStartingDateInBirthYear <- {
}
# 切割生日成為12星座區間
cutBirthdayByStartingDate <- {
}
# 改變星座區間類別名稱
birthdayCutRenameLevels <- {
}
levels(cutBirthdayByStartingDate) <- birthdayCutRenameLevels
as.character(cutBirthYearByStartingDate)
}Step2: Turn block programs into function
userBirthday <- ymd("1998-10-30")
get_userHoroscopes <- function(userBirthday)
{
# 取得生日年份
birthYear <- {
year(userBirthday)
}
# 取得生日年份的12星座起始日期
horoscopeStartingDateInBirthYear <- {
str_startingDate <-
paste0(birthYear,"-",horoscopes$sdate)
ymd(str_startingDate)
}
# 切割生日成為12星座區間
cutBirthdayByStartingDate <- {
cut(userBirthday,
breaks =
c(
ymd(
paste0(birthYear, "-01-01")
),
horoscopeStartingDateInBirthYear,
Inf
)
)
}
# 改變星座區間類別名稱
birthdayCutRenameLevels <- {
c("摩羯座", horoscopes$sign)
}
levels(cutBirthdayByStartingDate) <- birthdayCutRenameLevels
as.character(cutBirthdayByStartingDate)
}Step3: Test your function
get_userHoroscopes(ymd("1995-08-27"))
get_userHoroscopes(ymd("1970-05-18"))
get_userHoroscopes(ymd("2001-4-1"))In most cases, there is restriction on input argument class/type (can use is.XXX() functions to test). At the beginning of the function body, we want to assert that the restriction fits; otherwise, the function should stop execution and exit with some warning message. For this, assertthat::assert_that() is a very handy function to deliver the job.
get_userHoroscopes2 <- function(userBirthday){
assertthat::assert_that(is.Date(userBirthday),
msg="userBirthday should be a Date class object.")
get_userHoroscopes(userBirthday)
}get_userHoroscopes2("2010-01-22")get_userHoroscopes2(ymd("2020-01-22"))5.1.8 Input Argument default
\[f'(x_0) = \lim_{\epsilon \rightarrow 0}\ \frac{f(x_0+\epsilon)-f(x_0)}{\epsilon}\]
df0 <- function(f, epsilon=0.00001){
(f(epsilon)-f(0))/epsilon
}myFun <- function(x){
5*x^2-2*x+7
}df0(myFun)df0(myFun, epsilon = 1e-08)
df0(myFun, epsilon = 1e-10)Because defaults are the values that user mostly assume, they are better placed at the end of function arguments.
df0reverse <- function(epsilon=0.00001, f){
(f(epsilon)-f(0))/epsilon
}df0(myFun)# Error
df0reverse(myFun)# putting default at the front, force default users to put down the argument name f in every use.
df0reverse(f=myFun)5.1.9 R script
To reuse all your functions, you can save them in an R script file (file with file extension .R), then use source() to active them.
download.file(
"https://www.dropbox.com/s/zim84gg2g23g0pc/horoscopes.R?dl=1",
destfile="./horoscopes.R", mode="w"
)source("./horoscopes.R")5.2 Conditional Execution
Condition is an expression to tell computer to do/or not to do some task. When evaluated, it should return ONLY ONE logical value, sometimes it is called a Boolean flag in computer science.
logical (when evaluated)
one value
Conditional Execution(條件式執行) is also called control flow(流程控制).

User defined-condition(s) to determine how programming block(s) is(are) executed
5.2.1 if
ONE condition to determine whether ONE programming block should be executed.

ifis like a detour(繞道).
目標 If a customer has a voucher, deduct 20 from the total bill

set.seed(10739)
customers <- data.frame(
bills = sample(200:500, 10),
vouchers = sample(c(T,F), size=10, replace=T,
prob=c(0.4,0.6)
)
)
head(customers)bill <- customers$bills[[3]]
hasVoucher <- customers$vouchers[[3]]
totalBill <-
{
startingBill <- bill
if(hasVoucher)
{
bill <- bill - 20
}
message("You initial bill is ", startingBill,".\n",
"You final bill is ", bill)
bill
}
print(totalBill)get_totalBill <- function(bill, hasVoucher)
{
startingBill <- bill
if(hasVoucher)
{
bill <- bill - 20
}
message("You initial bill is ", startingBill,".\n",
"You final bill is ", bill, "\n")
bill
}purrr::map2(
customers$bills, customers$vouchers,
~get_totalBill(.x, .y)
)Conditional execution can be used to create mutiple ending stories:
\[f(x)=\sqrt{x},\ x\geq 0\]
目標 Interrupt function execution when x is negative
f <- function(x){
if(x<0)
{
stop("x has to be non-negative.")
}
sqrt(x)
}f(-2)
f(2)目標 Assign comments based on grades
comment_grade <- function(grade){
if(grade < 60) return("Don't give up. There is still hope.")
return("Good job. Keep going")
}df_grades <- data.frame(
grade=sample(50:95, 20, replace = T)
)
purrr::map_chr(
df_grades$grade,
comment_grade
) -> df_grades$comment5.2.2 Condition

grades <- c(55, 72, 40) # fail in first
# any one failed?
if(grades < 60) message("\nYes, someone failed")grades <- c(72, 55, 40) # fail in second
# any one failed?
if(grades < 60) message("\nYes, someone failed")Use
all()to flag if all failed.any()to flag if any failed.
grades <- c(72, 55, 82)
# any one failed?
if(any(grades < 60)) message("\nYes, someone failed")Set length warning into an error:
Sys.setenv("_R_CHECK_LENGTH_1_CONDITION_" = "true")grades <- c(55, 72, 82)
# any one failed?
if(grades < 60) message("\nYes, someone failed") # error now5.2.3 && ||
When using logical operations on logical values:
To judge if all conditions hold, a proper flag should be from
&&than&.To judge if any condition hold, a proper flag should be from
||than|.
5.2.3.1 &&
condition1: is a male condition2: older than 36
“is a male AND older than 36”
(isMale) & (olderThan36): Both conditions are checked to make a conclusion.(isMale) && (olderThan36): Conditions are check sequentially. When one is FALSE, there is no need to check subsequent conditions (more efficient); a FALSE is concluded.&&avoids unnecessary error produced by the subsequent condition.
目標 Check if student's economics grade is larger than 60
condition1: .$economics larger than 60.
due to input error in some records, impose second condition
condition2: the record is a list
(is a list) and (its economics element > 60)
grade1 <- list(
economics=55,
calculus=77
)
grade2 <- c(
economics=55,
calculus=77
)(is.list(grade1) & grade1$economics > 60)
(is.list(grade2) & grade2$economics > 60)(is.list(grade1) && grade1$economics > 60)
(is.list(grade2) && grade2$economics > 60)5.2.3.2 ||
目標
Check if a person is qualified for government subsidy
condition1: is a male condition2: older than 36
“is a male OR older than 36”
(isMale) | (olderThan36): Both conditions are checked to make a conclusion.(isMale) || (olderThan36): Conditions are check sequentially. When one is TRUE, there is no need to check subsequent conditions (more efficient); a TRUE is concluded.||avoids unnecessary error produced by the subsequent condition.
Qualifications for government subsidy:
age >= 65
other conditions
Suppose one person has an age of 75. He should be qualified, but the coding make other conditions generate an error.
myAge <- 75
if(myAge >=65 | stop("Error")){
"Qualified"
} else {
warning("Not qualified")
}if(myAge >=65 || stop("Error")){
"Qualified"
} else {
warning("Not qualified")
}When designing a control flow, the outcome from conditions should:
Always generate ONE flag signal.
Its AND/OR operators should be sequential (ie. using
&&/||) to avoid unnecessary errors and boost computation efficiency
5.2.4 if else

Mathematical function
\[ f(x) = \begin{cases} x/2 & \quad \text{if } x \text{ is even}\\ -(x+1)/2 & \quad \text{if } x \text{ is odd} \end{cases} \]
# 前提條件
x <- 4L
# 任務
fx <- {
# ending scenario 1:
{
x/2
}
# ending scenario 2:
{
-(x+1)/2
}
}# 前提條件
x <- 4L
# 任務
fx <- {
# ending scenario 1:
if(x %% 2 ==0)
{
x/2
} else
# ending scenario 2:
{
-(x+1)/2
}
}
fxelse must follow } immediately in the same line as
} elseOtherwise, the preceeding if(...){...} will be considered a complete if-control flow.
設計成函數
fx <- function(x)
{
# ending scenario 1:
if(x %% 2 ==0)
{
return(x/2)
} else
# ending scenario 2:
{
return(-(x+1)/2)
}
}fx(4L)
fx(7L)5.2.5 if-else if-else if-else

成績等級:
>=90: 優 # condition A80-89:良 # condition B70-79:尚可 # condition C70以下:待加強 # else
# 前提
grade <- 88
# 任務
comment <-
{
{
"優"
}
{
"良"
}
{
"尚可"
}
{
"待加強"
}
}# 前提
grade <- 88
# 任務
comment <-
{
if(grade>=90)
{
"優"
} else
if(grade >=80 && grade <=89)
{
"良"
} else
if(grade>=70 && grade <=79)
{
"尚可"
} else
{
"待加強"
}
}
commentcomment_grade <- function(grade){
if(grade>=90)
{
"優"
} else
if(grade >=80 && grade <=89)
{
"良"
} else
if(grade>=70 && grade <=79)
{
"尚可"
} else
{
"待加強"
}
}
comment_grade(65)If there are multiple TRUE flags from different if-condition expressions, ONLY the programming block follows the FIRST TRUE flag will be executed
comment_grade <- function(grade){
if(grade>=85)
{
"優"
} else
if(grade >=80 && grade <=89)
{
"良"
} else
if(grade>=70 && grade <=79)
{
"尚可"
} else
{
"待加強"
}
}
comment_grade(86)5.2.6 switch

sortedEmails <- list(
office=character(),
student=character(),
private=character()
)set.seed(2839)
emailFrom <- sample(
c("econ@gm.ntpu.edu.tw","classStudents@gm.ntpu.edu.tw","xxx@gmail.com","econStaff@gm.ntpu.edu.tw","yyyy@gmail.com"), 50,
replace=T
)
head(emailFrom, 10).x<- 3
commingEmail <- emailFrom[[.x]]Design each block first:
# Office
{
message("You have a message from office.")
nOffice <- length(sortedEmails$office)
sortedEmails$office[[nOffice+1]] <- commingEmail
sortedEmails
}
# Student
{
message("There is an email from student in your class.")
nStudent <- length(sortedEmails$student)
sortedEmails$student[[nStudent+1]] <- commingEmail
sortedEmails
}
# Private
{
message("A private message has come in.")
nPrivate <- length(sortedEmails$private)
sortedEmails$private[[nPrivate+1]] <- commingEmail
sortedEmails
}Design your condition sign secondly: What character values do you want to use?
office
student
private
condition_sgn <-
ifelse(
str_detect(commingEmail,"econ"), "office", commingEmail)switch(
condition_sgn,
"office"={
message("You have a message from office.")
nOffice <- length(sortedEmails$office)
sortedEmails$office[[nOffice+1]] <- commingEmail
sortedEmails
},
"classStudents@gm.ntpu.edu.tw"={
message("There is an email from student in your class.")
nStudent <- length(sortedEmails$student)
sortedEmails$student[[nStudent+1]] <- commingEmail
sortedEmails
},
{
message("A private message has come in.")
nPrivate <- length(sortedEmails$private)
sortedEmails$private[[nPrivate+1]] <- commingEmail
sortedEmails
}
)If there is a sign assigned to every switch blocks, when “other” cases happen, none of them will be executed. It is like bypassing the switch expression when others happen.
5.3 Iteration
將programming block {….} 立即反覆使用的語法。
Rule of thumb: never copy and paste more than twice.
But you do need to copy/paste twice, even three times, before you pick up the skill
5.3.1 Iteration flow
5.3.1.1 Iterates and Iterator
A programming block that contain iterator to represent a series of block programming with different iterator value (called iterates).
- iterator(疊代器) and iterates(疊代值): iterator is an object whose values changes according to the sequence of elements inside a vector (or list).
sampleData <- list(
list("男", 45), list("女", 32), list("男",50), list("男",33), list("女", 21)
)sampleData[[1]][[1]]
sampleData[[2]][[1]]
sampleData[[3]][[1]]
sampleData[[4]][[1]]
sampleData[[5]][[1]]Where are your iterates?
Recognize the repetitive patterns and the non-repeating parts, the latter is your source of iterates.
{ sampleData[[1]][[1]] }
{ sampleData[[2]][[1]] }
{ sampleData[[3]][[1]] }
{ sampleData[[4]][[1]] }
{ sampleData[[5]][[1]] }non-repeating on WHAT?
on
1, 2, 3, ..., 5on
sampleData[[1]], sampleData[[2]], sampleData[[3]], sampleData[[4]], sampleData[[5]]on
sampleData[[1]][[1]], sampleData[[2]][[1]], ..., sampleData[[5]][[1]]
Each one could be a collection of iterates. Let an object, say .x, be its iterator which is an object whose value is to be sequentially drawn from the iterates.
5.3.1.2 Iteration block
An iteration block is a programming block where all the iterates are replaced with the symbol of iterators to represent a series of similar programming flow.
For the following series of programming flow,
sampleData[[1]][[1]]
sampleData[[2]][[1]]
sampleData[[3]][[1]]
sampleData[[4]][[1]]
sampleData[[5]][[1]]- iterates:
1, 2, 3, ..., 5
{ sampleData[[.x]][[1]] }- iterates:
sampleData[[1]], sampleData[[2]], sampleData[[3]], sampleData[[4]], sampleData[[5]]
{ .x[[1]] }- iterates:
sampleData[[1]][[1]], sampleData[[2]][[1]], ..., sampleData[[5]][[1]]
{ .x }5.3.1.3 Iteration expression
Iteration expression: an expression of how iterator value generates.
ONE possible iteration expression in R is called for-loop:
for( iterator in vecotr(list)_of_iterates )- iterates:
1, 2, 3, ..., 5
for(.x in c(1,2,3,4,5))- iterates:
sampleData[[1]], sampleData[[2]], sampleData[[3]], sampleData[[4]], sampleData[[5]]
for(.x in sampleData)- iterates:
sampleData[[1]][[1]], sampleData[[2]][[1]], ..., sampleData[[5]][[1]]
for(.x in
list(sampleData[[1]][[1]], sampleData[[2]][[1]], sampleData[[3]][[1]],
sampleData[[4]][[1]], sampleData[[5]][[1]]) )5.3.1.4 Iteration
An iteration is an iteration expression followed by an iteration block
for( iterator in vector(list)_of_iterates )
{
iteration block
}5.3.2 for loop

sampleData[[1]][[1]]
sampleData[[2]][[1]]
sampleData[[3]][[1]]
sampleData[[4]][[1]]
sampleData[[5]][[1]]can be done via any one of the following iterations.
for(.x in c(1,2,3,4,5))
{
sampleData[[.x]][[1]]
}for(.x in sampleData)
{
.x[[1]]
}for(.x in
list(sampleData[[1]][[1]], sampleData[[2]][[1]], sampleData[[3]][[1]],
sampleData[[4]][[1]], sampleData[[5]][[1]]) )
{.x}
5.3.2.1 成績等第
At the end of a semester, teacher compiles students’ exam and homework grades as stored in grades object.
set.seed(2851)
exams <- sample(c(30:100, NA), 50, replace = T, prob = c(rep(0.8/71,71), 0.2))
homeworks <- sample(c(50:100, NA), 50, replace = T, prob = c(rep(0.9/51,51), 0.1))
grades <-
list(
exam=exams,
homework=homeworks
)A: >=80
B: [70, 80)
C: [60, 70)
F: [0, 60)
Define where to store your results:
results <-
list(
semesterGrade=vector("numeric", length(grades$exam)),
letterGrade=vector("character", length(grades$exam)),
emailContent=vector("character", length(grades$exam))
)Use JUST ONE element value to design your iteration flow prototype.
# 1st student
examX <- grades$exam[[1]]
homeworksX <- grades$homework[[1]]
## 學期總成績(作業40%,考試60%)
semesterGrade <- {
}
## 算出英文成績
letterGrade <- {
}
## 學期成績通知信內容
emailContent <- {
}1st student
examX <- grades$exam[[1]]
homeworksX <- grades$homework[[1]]
## 學期總成績(作業40%,考試60%)
semesterGrade <- {
examX <- ifelse(is.na(examX), 0, examX)
homeworksX <- ifelse(is.na(homeworksX), 0, homeworksX)
0.4*homeworksX + 0.6*examX
}
## 算出英文成績
letterGrade <- {
cut(semesterGrade,
breaks=c(-Inf, # F
60, # C
70, # B
80, Inf), # A
right = F) -> cut_semesterGrade
levels(cut_semesterGrade) <- c("F","C","B","A")
as.character(cut_semesterGrade)
}
## 學期成績通知信內容
emailContent <- {
glue::glue("親愛的同學:\n\n本學期你的考試成績為{examX},作業成績為{homeworksX},經換算學期成績為{semesterGrade}(為{letterGrade}等)。\n\n祝學習愉快")
}
## 存起來
results$semesterGrade[[1]] <- semesterGrade
results$letterGrade[[1]] <- letterGrade
results$emailContent[[1]] <- emailContentApply your design to SECOND element value to locate possible iterates definition.
2nd student
examX <- grades$exam[[2]]
homeworksX <- grades$homework[[2]]
## 學期總成績(作業40%,考試60%)
semesterGrade <- {
examX <- ifelse(is.na(examX), 0, examX)
homeworksX <- ifelse(is.na(homeworksX), 0, homeworksX)
0.4*homeworksX + 0.6*examX
}
## 算出英文成績
letterGrade <- {
cut(semesterGrade,
breaks=c(-Inf, # F
60, # C
70, # B
80, Inf), # A
right = F) -> cut_semesterGrade
levels(cut_semesterGrade) <- c("F","C","B","A")
as.character(cut_semesterGrade)
}
## 學期成績通知信內容
emailContent <- {
glue::glue("親愛的同學:\n\n本學期你的考試成績為{examX},作業成績為{homeworksX},經換算學期成績為{semesterGrade}(為{letterGrade}等)。\n\n祝學習愉快")
}
## 存起來
results$semesterGrade[[2]] <- semesterGrade
results$letterGrade[[2]] <- letterGrade
results$emailContent[[2]] <- emailContent- iterates: 1, 2, 3, …, 50
Iteration expression
for(.x in 1:50)Iteration block
{
examX <- grades$exam[[.x]]
homeworksX <- grades$homework[[.x]]
## 學期總成績(作業40%,考試60%)
semesterGrade <- {
examX <- ifelse(is.na(examX), 0, examX)
homeworksX <- ifelse(is.na(homeworksX), 0, homeworksX)
0.4 * homeworksX + 0.6 * examX
}
## 算出英文成績
letterGrade <- {
cut(semesterGrade,
breaks = c(
-Inf, # F
60, # C
70, # B
80, Inf
), # A
right = F
) -> cut_semesterGrade
levels(cut_semesterGrade) <- c("F", "C", "B", "A")
as.character(cut_semesterGrade)
}
## 學期成績通知信內容
emailContent <- {
glue::glue("親愛的同學:\n\n本學期你的考試成績為{examX},作業成績為{homeworksX},經換算學期成績為{semesterGrade}(為{letterGrade}等)。\n\n祝學習愉快")
}
## 存起來
results$semesterGrade[[.x]] <- semesterGrade
results$letterGrade[[.x]] <- letterGrade
results$emailContent[[.x]] <- emailContent
}Iteration
results <-
list(
semesterGrade=vector("numeric", length(grades$exam)),
letterGrade=vector("character", length(grades$exam)),
emailContent=vector("character", length(grades$exam))
)
for(.x in 1:50)
{
examX <- grades$exam[[.x]]
homeworksX <- grades$homework[[.x]]
## 學期總成績(作業40%,考試60%)
semesterGrade <- {
examX <- ifelse(is.na(examX), 0, examX)
homeworksX <- ifelse(is.na(homeworksX), 0, homeworksX)
0.4 * homeworksX + 0.6 * examX
}
## 算出英文成績
letterGrade <- {
cut(semesterGrade,
breaks = c(
-Inf, # F
60, # C
70, # B
80, Inf
), # A
right = F
) -> cut_semesterGrade
levels(cut_semesterGrade) <- c("F", "C", "B", "A")
as.character(cut_semesterGrade)
}
## 學期成績通知信內容
emailContent <- {
glue::glue("親愛的同學:\n\n本學期你的考試成績為{examX},作業成績為{homeworksX},經換算學期成績為{semesterGrade}(為{letterGrade}等)。\n\n祝學習愉快")
}
## 存起來
results$semesterGrade[[.x]] <- semesterGrade
results$letterGrade[[.x]] <- letterGrade
results$emailContent[[.x]] <- emailContent
}5.3.3 while loop

Iteration expression: Use condition flag to signal if stay inside the iteration block.
TRUE: stay
FALSE: exit
Construct your iterates and iteration block as before; BUT
Augment your iteration by (1) iterate generation in the front; and (2) flag generation in the back.
5.3.3.1 Mimic for loop
目標 取出sampleData每一個元素底下的第一個元素值(即性別值)# iterates: 1,2,3,4,5
# iteration block
{
sampleData[[.x]]
}5.3.3.2 Iterate generation
- while-loop won’t iterate
.xvalue for you. You have to program it inside the iteration block yourself.
.x <- .x + 1 # if .x exists in your environment5.3.3.3 Iteration condition
while(flag)- Exit if flag is FALSE
5.3.3.4 Flag generation
After each iteration, we need to judge if we should continue for the next iterate. Therefore, flag generation should:
attach at the end of the iteration block;
represent a conditon to continue iteration.
In mimicing for loop, the continuation condition is when we haven’t finished the last iterate
flag <- (.x < 5) # continuation flag condition with definite iterates5.3.3.5 Iteration flow
while(flag)
{
.x <- .x+1 # Iterate generation
sampleData[[.x]][[1]]
flag <- (.x < 5) # Continuation flag
}- (Most of time) Need to give initial iterate, and initial flag.

rm(list=ls())
sampleData <- list(
list("男", 45), list("女", 32), list("男",50), list("男",33), list("女", 21)
).x <- 0 # initial iterate
flag <- TRUE # initial flag
while(flag)
{
.x <- .x+ 1 # Iterate generation
print(sampleData[[.x]][[1]])
flag <- (.x < 5) # continuation flag
}5.3.3.6 Safe guard while-loop
On and off we encounter indefinite while loops trap (the iterations never stop) due to design flaw. Therefore, it is very common to throw in two safe guards:
maximal iterate restriction
print your progress
.x <- 0 # initial iterate
flag <- TRUE # initial flag
cat('Iterate .x starts at 0, and continue to\n')
while(flag && .x <= 100) # throw in maximal iterate restriction
{
.x <- .x+ 1 # Iterate generation
print(sampleData[[.x]][[1]])
flag <- (.x < 5) # continuation flag
cat('.x = ', .x, ' complete\n')
}5.3.3.7 Guess Number
Computer randomly drawed a number from 10 to 50, denoted as x0. If user guesses a number less than x0, show “Higher” on the screen. If larger than x0, show “Lower” on the screen. When guess incorrectly, user can guess again until guessing correctly, then prompt “BINGO!!! You guess it right after XXX trials” on the screen where XXX is number of iterations have taken.
A smaller task: user only guesses one time.
# computer pick a number
.computerPick <- {
}
# iteration time
.x <- 1
# user guess
userGuess <- readline("What's your guess?")
# conditional execution of 3 blocks
{
"Higher"
}
{
"Lower"
}
{
glue::glue("BINGO!!! You guess it right after {.x} trials")
}# computer pick a number
.computerPick <- {
sample(10:50, 1)
}
# iteration time
.x <- 1
# user guess
userGuess <- readline("What's your guess?")
# conditional execution of 3 blocks
result <-
if(as.integer(userGuess) < .computerPick)
{
"Higher"
} else
if(as.integer(userGuess) > .computerPick)
{
"Lower"
} else
{
glue::glue("BINGO!!! You guess it right after {.x} trials")
}
message(result)iteration block
# computer pick a number
.computerPick <- {
sample(10:50, 1)
}
# iteration block
{
# iteration generation
# # iteration time
# .x <- 1
# user guess
userGuess <- readline("What's your guess?")
# conditional execution of 3 blocks
result <-
if (as.integer(userGuess) < .computerPick) {
"Higher"
} else
if (as.integer(userGuess) > .computerPick) {
"Lower"
} else {
glue::glue("BINGO!!! You guess it right after {.x} trials")
}
message(result)
# continuation flag
}complete while loop
# computer pick a number
.computerPick <- {
sample(10:50, 1)
}
# iteration time
.x <- 0
flag <- T
while(flag)
# iteration block
{
# iteration generation
.x <- .x + 1
# user guess
userGuess <- readline("What's your guess?")
# conditional execution of 3 blocks
result <-
if (as.integer(userGuess) < .computerPick) {
"Higher"
} else
if (as.integer(userGuess) > .computerPick) {
"Lower"
} else {
glue::glue("BINGO!!! You guess it right after {.x} trials")
}
message(result)
# continuation flag
flag <- ! stringr::str_detect(result, "BINGO")
}5.4 The marvels of programming block
{...} 裡面「最後一個expression」的「可視(visible)值」可以當做值用來賦予一個物件元素值。也就是說
result <- {...} # 或
{...} -> resultresult的值會是{...}裡最後一個expression的可視結果
5.4.1 Pseudo-code vessels
step1_object <-
{
...
}
step2_object <-
{
...
}# Task: solving market equilibrium
# find p that makes qd=qs
Qd <- c("10"=5, "8"=10, "6"=15, "5"=20)
Qs <- c("10"=20, "8"=18, "6"=15, "5"=10)
excess_demand <-
{
Qd-Qs
}
equilibrium <-
{
whichIsZero <- which(excess_demand==0)
p <- names(excess_demand)[[whichIsZero]]
q <- Qd[[p]]
list(
p=as.numeric(p),
q=q
)
}
equilibrium5.4.2 Function body
function(input1, input2)
{
input1
input1 input2
input2
}get_equilibrium <- function(Qd, Qs)
{
excess_demand <-
{
Qd-Qs
}
equilibrium <-
{
whichIsZero <- which(excess_demand==0)
p <- names(excess_demand)[[whichIsZero]]
q <- Qd[[p]]
list(
p=as.numeric(p),
q=q
)
}
return(equilibrium)
}Qd <- c("10"=5, "8"=10, "6"=15, "5"=20)
Qs <- c("10"=20, "8"=18, "6"=15, "5"=10)
get_equilibrium(Qd, Qs)5.4.3 Conditional blocks
if()
{
} else
{
}flag_mary <- T
if(flag_mary)
{
"Hi, Mary."
} else
{
"Hi, everyone."
}Condition execution can return value following the block programming rule:
flag_mary <- F
greeting <-
if(flag_mary)
{
"Hi, Mary."
} else
{
"Hi, everyone."
}
greetingBut never put assignment after the last condition execution block. It will be the last block that control the returned value.
if(flag_mary)
{
"Hi, Mary."
} else
{
"Hi, everyone."
} -> greeting
greeting5.4.4 Iteration blocks
for(.x in ...)
{
.x
.x
}sampleData <- list(
list("Jenny", 12),
list("Mary", 10),
list("Bob", 35)
)
introduction <- vector("list", length(sampleData))
count <- 0
for(.x in sampleData){
count <- count+1
introduction[[count]] <- paste0(.x[[1]], " is ", .x[[2]])
}
introductionpurrr::map(
sampleData,
~{
paste0(.x[[1]], " is ", .x[[2]])
}
)purrr::map is a functional that can produce iteration result.
get_sumx <- function(sumx, x){
}5.5 綜合練習
1. Taylor Expansion
For any properly behaved function \(f(x)\), its value of \(x\) around some \(x_0\) value (but not too far away) can be approximated by a polynomial function of degree 2, based on the following Taylor expansion: \[f(x)\sim f(x_0)+f'(x_0)(x-x_0)+f''(x_0)\frac{(x-x_0)^2}{2},\] where \(f'(x_0)\) and \(f''(x_0)\) are the first derivative and the second derivative of \(f\) at point 0.
For example, we want to know \(f(0.003)\), if we believe 0.003 is close enough to 0, then we can use \(ftb(0.003)\) to represent \(f(0.003)\) where
\[ftb(0.003) = f(0)+f'(0)(0.003-0)+f''(0)\frac{(0.003-0)^2}{2}\] In other words for any \(x\) around 0, its \(f(x)\) value is about: \[ftb(x) = f(0)+f'(0)(x-0)+f''(0)\frac{(x-0)^2}{2}\] To construct \(ftb(x)\) we need to numerically compute \(f'(0)\) and \(f''(0)\)
1.1 f’(x_0)
Numerically we can approximate the first derivative of \(f\) based on \[\frac{f(x_0+\epsilon)-f(x_0)}{\epsilon},\] for some very small \(\epsilon\) value.
Design a first derivate function, df, which takes input arguments f (any function with one argument), x_0 (a number), and epsilon (a number) that returns the value as the approximation formula described in the above. Furthermore, the default of x_0 is 0, and the default of epsilon is 0.00001.
1.2 safe guard your function
Place assertion in you df function, renamed it df_assert, so that when user’s f is not a function class, the function stops and shows “Input f is not a function.” When user’s f takes more than one arguments, like f(x,y), the function stops and shows “Sorry the current function deals with only one-dimensional input function.”
1.3 f’’(x_0)
Second derivative is can be approximated using the proximated first derivative we get from the previouse question, so that
\[f''(x_0)\sim \frac{f'(x_0+\epsilon)-f'(x_0)}{\epsilon},\]
for some very small \(\epsilon\) value. Given \(df\) function designed previously, the approximated second derivative is: \[\frac{df(x_0+\epsilon)-df(x_0)}{\epsilon}\] Use the above formula to design the second derivative function d2f, which takes input arguments f (any function with one argument), x_0 (a number), and epsilon (a number).
d2f also has x_0 default at 0 and epsilon default at 0.00001. And whenever x_0 or epsilon set to other values, so are changed the counterpart arguments in df.
1.4 ftb
\[\tilde{f}(x)\equiv f(x_0)+f'(x_0)(x-x_0)+f''(x_0)\frac{(x-x_0)^2}{2}\] Design a ftb function which returns \[f(x_0)+f'(x_0)(x-x_0)+f''(x_0)\frac{(x-x_0)^2}{2},\] where \(f'(x_0)\) and \(f''(x_0)\) are computed numerically with your previous df and d2f functions. Function ftb has input arguments f , x, x_0 and epsilon, the latter two of which have default values 0 and 0.00001. When they are changed, so are the corresponding argument values of df and d2f.
How good is Taylor expansion of degree 2 approximation?
originF <- function(x) sin(x)+sqrt(5*x^2-x+1)*exp(x)originF(0.0002) # 1.0003
ftb(originF, 0.0002) # 1.0003
originF(0.02) # 1.030977
ftb(originF, 0.02) # 1.0309512. 星座、歲次、時辰
birthdays <-
sample(
seq(ymd_hm("1973-01-02 00:00"),
ymd_hm("2020-12-31 00:00"),
by="hour"),
100
)3. 交友軟體
執行以下程式可以得到NTPUmeet交友軟體的1000名會員資料members及由它粹取的會員編號memberIds,
members <- jsonlite::fromJSON("https://www.dropbox.com/s/olji1q29t2autec/ntpumeetMembers.json?dl=1", simplifyDataFrame = F)
memberIds <- purrr::map_chr(members, ~{.x[["memberID"]]})- each element in members is a list of 7 representing one member’s information.
For each of the following question, it will start with what the global environment should have up to the question. Those mentioned objects in the global environment should really exist in your global environment, and are available for you to use even they are not your function input arguments.
However, for those not mentioned other than input arguments, you should not include them in your function body.
3.1 Member login
global environment has: members, memberIds
When a user logs in NTPUmeet, the first thing the app does is to pull out this member’s information based on this user’s login information, assumed to be his/her memberID. Almost at the same time, the app will update his/her latestGPS value based on his/her current GPS read, provided by your cell phone device. Write a function called appLogin which takes the sampled memberID and currentGPS as input arguments and return a list of 7 representing this user.
Complete the appLogin function design:
appLogin <- function(memberID, currentGPS){
}
# appLoginFor function testing, you can use memberID and currentGPS provided by the following data block:
memberID <- memberIds[[582]]
currentGPS <-
c(
sample(
seq(24.94062,24.94788, by=0.00001),1),
sample(
seq(121.36293,121.37222, by=0.00001),1)
)The following question require the global environment exists currentUser created by
currentUser <- appLogin(memberID, currentGPS)If you can not successfully design appLogin() function, you can use the following code to generate a proxy currentUser instead:
currentUser <- members[[582]]The environment also has data information members and memberIds for your use.
3.2 Refine
global environment has: members, memberIds, appLogin, currentUser
When a NTPUmeet user refreshes the app, it will show 30 members who are closest to him/her based on the user’s lastestGPS (which is already updated after appLogin function executed). However, the refreshed list should not contain any member in the user’s blocks list, and those that are in the user’s likes list should be placed in the front of the list.
Run the following code to get a vector of 100 member IDs, otherMembers:
otherMembers <- sample(memberIds[which(memberIds != memberID)],100)Create a refine_byLikesBlocks function which only takes one input argument otherMembers and return its subset vector that has removed the element values appearing in currentUser’s blocks, and for those remaining element values which are in currentUser’s likes element they will be moved to the front of the returned vector.
refine_byLikesBlocks <- function(otherMembers){
}
# refine_byLikesBlocks3.3 Refresh
global environment has: members, memberIds, appLogin, currentUser, refine_byLikesBlocks
Create a refresh function that takes no input argument. When it is executed, a character of 30 members’ memberID out of all 1000 members is returned. They are sorted by their distance to the current user (based on the latestGPS values) from the closest to the furthest. And they must meet likes/blocks refinement criteria.
Distance can be calculated from their lastesGPS values. Suppose one is c(10,11), the other is c(15,22). Their distance is sqrt((15-10)**2+(22-11)**2)). To get the order of a numeric vector say x, use orderX <- order(x) to get orderX which is the position indices that make x[orderX] be sorted from the smallest to the largest values. (hint: functions you might need. sum(), sqrt())
refresh <- function(currentUser){
}
# refresh4. 故宮畫藏查詢App
The National Palace Museum(國立故宮博物院)is trying to develop an app to facilitate user’s search of painting creators.
執行以下程式下載200幅故宮中國畫作資訊(painting):
jsonlite::fromJSON("https://www.dropbox.com/s/ttw2j7nitc35vfx/palaceMuseumPainting.json?dl=1", simplifyDataFrame = F) -> painting4.1 Full list of the painters
A full list of painters are needed. In order to provide user a menu of painters to choose in the App.
PLEASE organize a character vector named allCreators which gives all creator names in the sequence of painting elements order. The length of our output will be 200, and PLEASE assign the creator’s name as “無名氏” if they are not provided.
4.2 Creator collection
Corresponding to each painter from allCreators in the previous question, there should be a list of all this painter’s artworks.
Consider creatorX
creatorX <- "仇英" # 改題時名稱會隨機取出PLEASE Create creatorX_artworks as a list of creatorX’s artwork information.
For each one of creatorX’s artworks, the app needs the following information: Title, Id(Identifiers), and ICON (which is the url of the painting), stored as a list of 3, all charactor class, with element names: Title, Id, and Icon. All this creator’s list-of-3 artwork information collectively forms a big list of all his artworks, called creatorX_artworks. Each element in this object is a list-of-3 information regarding one artwork.
PLEASE be aware of the term 主要題名: in the beginning of Title, the term 作品號: in the beginning of Identifier, and the term 作者: in the beginning of Creator are all dropped.
One artwork list of 3 should be like:
List of 3
$ Title: chr "明仇英玉洞燒丹 卷"
$ Id : chr "中畫00002400000"
$ Icon : chr "http://painting.npm.gov.tw/getCollectionImage.aspx?ImageId=667984&r=1165509944"4.3 Creator-based Journey
PLEASE leverage the output from ans41 and ans42 to build a function called get_creatorSeries. The input of the function will be a name of a certain painter, and the output of the function will be the list of his painting pieces (as creatorX_artworks in the previous question).
PLEASE add assertthat::assert_that(is.character(CreatorName), msg="The Input Creator Name should be a character class object.") in the very beginning of your function.
tips:
formals(get_creatorSeries)will shows $CreatorName
You can assume that when the App initiates, allCreator and painting will populate user’s global environment.
get_creatorSeries("王淵")4.4 User interaction
Create generate_creatorInteractiveSession function, which behaves like get_creatorSeries except that its return has two differences:
each element in the returned list are named by the artwork title.
each element in the returned list has one more named element called browse which is a function that will launch your browser to the page based on the Icon url of the artwork. (
browseURL(url)function can open your browser to visit theurlpage.)
You can use the function you created earlier in your function body.
generate_creatorInteractiveSession("王淵") -> results
results$`元王淵蓮池禽戲圖 卷`$browse()
results$`明仇英仿趙伯駒煉丹圖 軸`$browse()4.5 Dynasties Identification
Please write the function called get_painting_dynasty with one function input called PaintingName. The function works as following:
When we enter the name of the painting, for example the 4th painting "主要題名:五代後蜀滕昌祐蝶戲長春圖 卷",
it will return us the dynasty of it, namely [1] "五代後蜀". The output is in character class rather than the list.
4.6 Subjects Identification
Please write another function called get_painting_subjects with one function input called PaintingName. The function works as following:
When we enter the name of the painting, for example the 20th painting "主要題名:元王淵鷹逐畫眉 軸",
it will return us the subjects of it, namely [1] "鷹" "畫眉" "竹" "蘆葦". The output is in character class rather than the list.
for the painting with no subject, the output will be character(0).
4.7 Special Exhibition Preparation
For the forthcoming exhibition, we need to build the more handy query for our visitors. Please build the function called get_painting_withDS with one input argument PaintingName. The output is always a list of that certain painting with the elements Dynasty, Title, Id, Subjects and Icon.
Leveraging the get_painting_dynasty and get_painting_subjects functions can be practical.
Also, be aware of the term 主要題名: in the beginning of Title, the term 作品號: in the beginning of Identifier are dropped. Also, Subjects are concluded in one element rather than the Subjects.X in separate.
To be more specific, when we enter the 1st painting with its title "主要題名:唐閻立本職貢圖 卷", the structure of our output will be like:
List of 5
$ Dynasty : chr "唐"
$ Title : chr "唐閻立本職貢圖 卷"
$ Id : chr "中畫00000100000"
$ Subjects: chr [1:14] "奇石" "孩童" "蕃族" "馬" ...
$ Icon : chr "http://painting.npm.gov.tw/getCollectionImage.aspx?ImageId=652764&r=476948028"4.8 Guide to Dynasty-based Exhibition
The museum is going to have a Dynasty-based exhibition, we need provide visitors the guide to enjoy the certain painting. Whenever the visitor enter the name of painting, the app will tell him/her where to go:
Please write the function called get_instruction with one input PaintingName, and the output will be one of the possible message below and also the exact aforementioned information from our get_painting_withDS function in ans47.
- If the painting is belonged to Qing Dynasty(清朝), please provide him message
"Please go to 4F" - If the painting is belonged to Ming Dynasty(明朝), please provide him message
"Please go to 3F" - If the painting is belonged to Song Dynasty(宋朝), please provide him message
"Please go to 2F" - For the rest of the painting, please provide him message
"Please ask our reception"
4.9 Special Exhibition of Top-10 Subjects in Qing Dynasty
We are going to run the campaign for our Top-10 subjects in Qing Dynasty(清朝). Every painting might have zero, one, or even multiple subjects. If any of its subjects belonged to the Top-10 subjects in Qing Dynasty. We will recognize it as a part of this Special Exhibition.
Please build a function called get_special_instruction with one input PaintingName, and the output will be the one of the possible message below and also the exact aforementioned information from our get_painting_withDS function in ans47.
If the painting is belonged to this special exhibition, please provide him message
"Please visit our building A"If the painting is not belonged to this special exhibition, please provide him message
"The painting is not belonged to our special exhibition."
5. 交友軟體改良

This exercise is to help you understand function environment. First, run the following code to clean your Global environment
rm(list=ls())Second, execute the following chunk to obtain R script file “NTPUmeetCore.R”
# download NTPUmeetCore.R script file
xfun::download_file("https://www.dropbox.com/s/54khnc8k607amw1/NTPUmeetCore.R?dl=1")
# open the file to take a look
file.edit("./NTPUmeetCore.R")When NTPUmeet is launched, “NTPUmeetCore.R” is sourced into user’s cellphone global environment. Populate it with various objects including data and functions.
# source the script to you global environment
source("./NTPUmeetCore.R")Among all the functions, appLogin is launched immediately. A member logs in with memberID members[[35]]$memberId and current GPS read c(24.95, 121.375) is like
library(purrr)
library(stringr)
currentUser <- appLogin(members[[35]]$memberID, c(24.945, 121.367))which adds one more object currentUser to the cellphone global environment, and at the same time updates members[[35]]
# check and see the update
members[[35]]$latestGPSFollowing appLogin, function refresh is activated. The function basically shows current user the closest 30 members from global environment members who are within maxDistance, sorted from the closest to the furthest and fit the user’s like/block restrictions.
The team sketch out the programming blocks for refresh:
# 前提
members
currentUser
# 任務
members30 <- {
# 1 選出在current User GPS maxDistance範圍內的members, 同時排序近到遠
membersWithinDistance <- {
}
# 2 過濾membersWithinDistance以滿足likes/blocks限制
refined_membersWithinDistance <- {
}
refined_membersWithinDistance # 做為最後可視值
}Among two programming blocks, the team put down
membersWithinDistance <- {
get_withinDistance_sorted(currentUser, maxDistance = 0.000856)
}This require them to design the function get_withinDistance_sorted.
5.1 get_withinDistance_sorted
Design get_withinDistance_sorted function which takes currentUser and maxDistance as the second argument who has a default value of 0.000856; and it will return memberID values of those among 1000 members who are close to the user within maxDistance range, the memberID are orderd from the closest member to the furthest.
Input arguments: maxDistance a number, default at 0.000856.
Returned valued: a character vector of memberID values whose corresponding members are within the maxDistance range, and are orded from the closest member to the furthest.
get_withinDistance_sorted(currentUser)5.2 refresh
Design refresh function that shows current user the closest 30 members from global environment members who are within maxDistance, sorted from the closest to the furthest and fit the user’s like/block restrictions.
refresh()5.3 likes
currentUser may choose to like some member, say the following randomly drawn member member2like:
member2like <- members[[sample(1:1000,1)]]
member2likeOnce the user likes this member. The memberID of member2like will be added to his likes element in currentUser. However, the action can not go against member2like’s preference
member2like$preference$wantSameMajor (可接受同系) =T, 則學號學系碼(學號第5,6碼)必需相同; F 則沒限制。
$wantSenior=T(只要三,四年級), 則入學年必需是107或之前; F 則沒限制。
$alreadyGraduatedAllowed=F(不允許已畢業的), 則入學年不可以是106之前(不含106, 106可以); T 則沒限制。
$genderPreference(性別偏好)= “男”,“女”或"均可
Design a like function which has two input arguments, currentUser and member2like, it returns currentUser. The returned currentUser$likes might be updated, if he passed all the preference requirement of member2like$preference. If he did not pass all the preference requirement, the returned currentUser is the same as before, and a message of “Sorry the member will not like you.” on the screen
like <- function(currentUser, member2like){
return(currentUser)
}5.5.0.1 5.4 New member
6. Rock-Paper-Scissor
6.1 One round
設計一個剪刀,石頭,布的遊戲,當使用者執行
oneGame <- gameStart()會產生一個oneGame list of 3, 使用者可以執行以下三個可能招式:
# 出剪刀
oneGame$scissor()
# 出石頭
oneGame$rock()
# 出布
oneGame$paper()各別招式函數內部會有電腦隨機由“scissor”, “rock”, “paper”選一式出招。
每個招式會回值以下3個可能的list之一:
list(you=你的招式, computer=computer招式, 1),表示勝過電腦
list(you=你的招式, computer=computer招式, 0),表示平手
list(you=你的招式, computer=computer招式, -1),表示輸給電腦
請設計gameStart函數。
6.2 Multiple rounds
寫一個剪刀、石頭、布遊戲函數gameStart2,玩家與電腦對決誰先得到3分誰便勝出。
When run gameStart2(): (the following is pseudo-code)
Initiate user score, userScore, to be 0. Contifuation flag to be TRUE
Start loop:
2.0 Check continuation flag, if TRUE, continue, FALSE, jump to step 3.
2.1 Screen show “choose your action: 1. scissor, 2. rock, 3. paper” to obtain user input, userInput
2.2 Computer randomly chooses its action, computerPick.
2.3 Check win/loose, update userScore.
2.4 update continuation flag.If userScore= -3, screen show “you loose”; =3, screen shows “you win”.
# 1. Initiate user score, **userScore**, to be 0. Continuation flag to be TRUE
userScore <- 0
flag <- TRUE
# 2. Start loop:
# 2.0 Check continuation flag, if TRUE, continue, FALSE, jump to step 3.
while(flag)
{
# 2.1 Screen show "choose your action: 1. scissor, 2. rock, 3. paper" to obtain user input, **userInput**
# 2.2 Computer randomly chooses its action, **computerPick**.
# 2.3 Check win/loose, update **userScore**.
# 2.4 update continuation flag.
}
# 3. If **userScore**= -3, screen show "you loose"; =3, screen shows "you win".7. 累積學分查詢
Take Sociology Department students as an example.
社會學系:大學部畢業學分規定
- “本系”指學生所屬學系,“本系課程”指開課系所與學生本系相同;“外系課程”指開課系所(不含非正規學制單位,如軍訓室、體育組等)與學生本系不同
7.1
Given student transcript transcriptX, we should be able to find his current major based on the latest deparment name shown on transcriptX$系級.
8. 課程查詢
執行以下程式可下載國立臺北大學107學年課程資訊
jsonlite::fromJSON("https://www.dropbox.com/s/t09nrzwx8mw6azn/courses107.json?dl=1") -> courses1078.1 課表
9. Matching
Constantly we face the problem of matching in our life. Should I accept him/her as my boyfriend/girlfriend? Should I accept this job offer? Should I enroll in this class? The ultimate problem of matching starts from search, to acceptance, then to separation (if that day comes). In this exercise, we design various functions to enforce various matching mechanism.
Learning peer matching
After the midterm, teacher Martin decides to match students to form various study groups so that those who scored well can help those who did poorly in the exam. The only information he can observer regarding students’ true ability (this information is called signal by economists) is their midterm grades.
IDletters <- expand.grid(LETTERS, LETTERS)
allIDcombinations <- paste0(IDletters$Var1, IDletters$Var2)
set.seed(2038)
classGrades <- list(
ID=sample(allIDcombinations, 56),
grade=sample(0:100, 56)
)Let grades = { classGrades$grade sorted from the smallest to the largetst } so that \[grades[[1]]\leq grades[[2]]\leq \dots\leq grades[[56]]\]
and let \(IDs\) be a character vector of IDs corresponding to each grades element value.
9.1 sort_grades
Design a helper function sort_grades so that given classGrades it returns its sorted version of list.
input argument: classGrades
return value: a list of 2, named ID and grade (the same as input argument element names). The value of grade element is the sorted grades as described earlier. The value of ID element is its corresponding ID as described earlier.
classGrades
map(sort_grades(classGrades), head)Suppose Martin wants each group to have 4 members.
9.2 obtain_random4
Design a function that can randomly draw 4 members from any list that
Input argument: a list of 2 containing the information of students’ IDs and grades. The argument has the same structure of classGrades (meaning the 2 elements have names of ID and grade. The former element is a character vector, the latter element if a numeric vector——and both elements have equal length)
Return value: a list of 2. One element (named drawnGroup) represents the drawn group members; the other element (named remainingStudents) keeps the remaining students’ information. Both elements have the same structure as classGrades in terms of its underlying element names, classes and equal length across elements property.
result <- obtain_random4(classGrades)
str(result)List of 2
$ one_group :List of 2
..$ ID : chr [1:4] "DI" "WS" "ZC" "DB"
..$ grade: int [1:4] 88 43 46 39
$ remaining_students:List of 2
..$ ID : chr [1:52] "UE" "ML" "CL" "KR" ...
..$ grade: int [1:52] 3 5 6 9 10 11 13 14 16 19 ...9.3 obtain_polar4
The other possible drawing method Martin is thinking is to put 4 students with polarized grades as a group. Suppose we have \[grades[[1]]\leq grades[[2]] \leq\dots\leq grades[[10]]\]
It means putting the lowest two grades students (i.e. \(grades[[1]],\ grades[[2]]\)) with the highest two grades students (i.e. \(grades[[9]],\ grades[[10]]\))
Design a function called obtain_polar4 that can draw 4 members from classGrades based on the above polarized matching rule.
Input argument: a list of 2, with names ID and grade.
Return value: a list of 2. Element one is named drawnGroup, which is a list of 2, with names ID and grade, and each element has four values from the 4 drawn-from-input-argument students’ IDs and grades. Element two is named remaining_students, which is a list of 2, with names ID and grade, and each element has the remaining students’ IDs and grades in the input argument.
9.4 Randamized matching
Design a function match_random which takes in classGrades
and return a list of length(classGrades$ID)/4, each element is a list of 2, containing the information of 4 randomly drawn students information of ID and grade (has the same structure of classGrades)
results <- match_random(classGrades)
str(results)List of 14
$ :List of 2
..$ ID : chr [1:4] "QG" "YT" "DI" "KR"
..$ grade: int [1:4] 42 70 88 9
$ :List of 2
..$ ID : chr [1:4] "KS" "HB" "QK" "DF"
..$ grade: int [1:4] 34 59 55 96
:
$ :List of 2
..$ ID : chr [1:4] "EP" "OF" "CL" "ML"
..$ grade: int [1:4] 75 47 6 59.5 Polarized matching
10. Vectorized function
In 5.2.5 we designed a grade commenting function comment_grade:
comment_grade <- function(grade){
if(grade>=90)
{
"優"
} else
if(grade >=80 && grade <=89)
{
"良"
} else
if(grade>=70 && grade <=79)
{
"尚可"
} else
{
"待加強"
}
}However, it can only comment on one grade a time
comment_grade(83)
comment_grade(55)Trying to do the following will produce a wrong outcome:
comment_grade(c(83,55))Please design vec_commentGrade function so that it can comment on a vector of numerical grades.
For vec_commentGrade,
input argument: grades, a numeric vector.
return value: a character vector of length the same as grades input value.
You can take comment_grade function as existing in the function environment of vec_commentGrade.
A function that can be applied to a vector of elements, as well as applyied to each element then collecting them as a vector, is called a vectorized function. In our case vec_commentGrade is a vectorized function since
vec_commentGrade(c(83,55)) # and
c(vec_commentGrade(83), vec_commentGrade(55))produce the same result.
11. Root of a function

Given a function \(f(x)\), we want to solve for \(x^*\) which makes \(f(x^*)=s\). We say that \(x^*\) is the root of \(f(x^*)-s=0\). Since no matter what \(s\) value is, if we include \(-s\) in the definition of \(f(x)\), the solution is always about \(f(x^*)=0\), most of the time we read the definition of root as the solution to \(f(x^*)=0\) (where \(s\) is already included inside the function definition). In this exercise, you are guided to solve the root (in the definition of \(f(x^*)=0\)) of any given function numerically.
11.1 Mathematical function
Consider a function \(f(x)\) as:
\[f(x)=\sin(x)/(\tanh(\sqrt{x}))-x^3-0.3\]
Define a function called f to represent the above function definition. (In R, there are functions called, sin, tanh, and sqrt(x) for \(\sqrt{x}\))
f <- function(x){
}
# f11.2 x and f(x)
Generate a sequence of x values from 0.04, 0.06, 0.08, ….to 1, saved inside rangeX. Each element values differs from the other by 0.02. Also get their \(f(x)\) values saved inside object fx. When you complete the two objects saved them inside a list called f_mapping defined in the following code chunk.
# Your code to get fx and rangeX
f_mapping <-
list(
fx=fx,
x=rangeX
)
# f_mapping11.3 Mapping
Write a function get_f_mapping, so that given inputs f and rangeX it will return a list of 2 with the same structure as f_mapping
get_f_mapping <- function(f, rangeX){
}
# get_f_mapping11.4 Root-covered interval
Run the following program, you will see a plot.
with(
f_mapping,
{
plot(x=x, y=fx)
abline(h=0)
}
)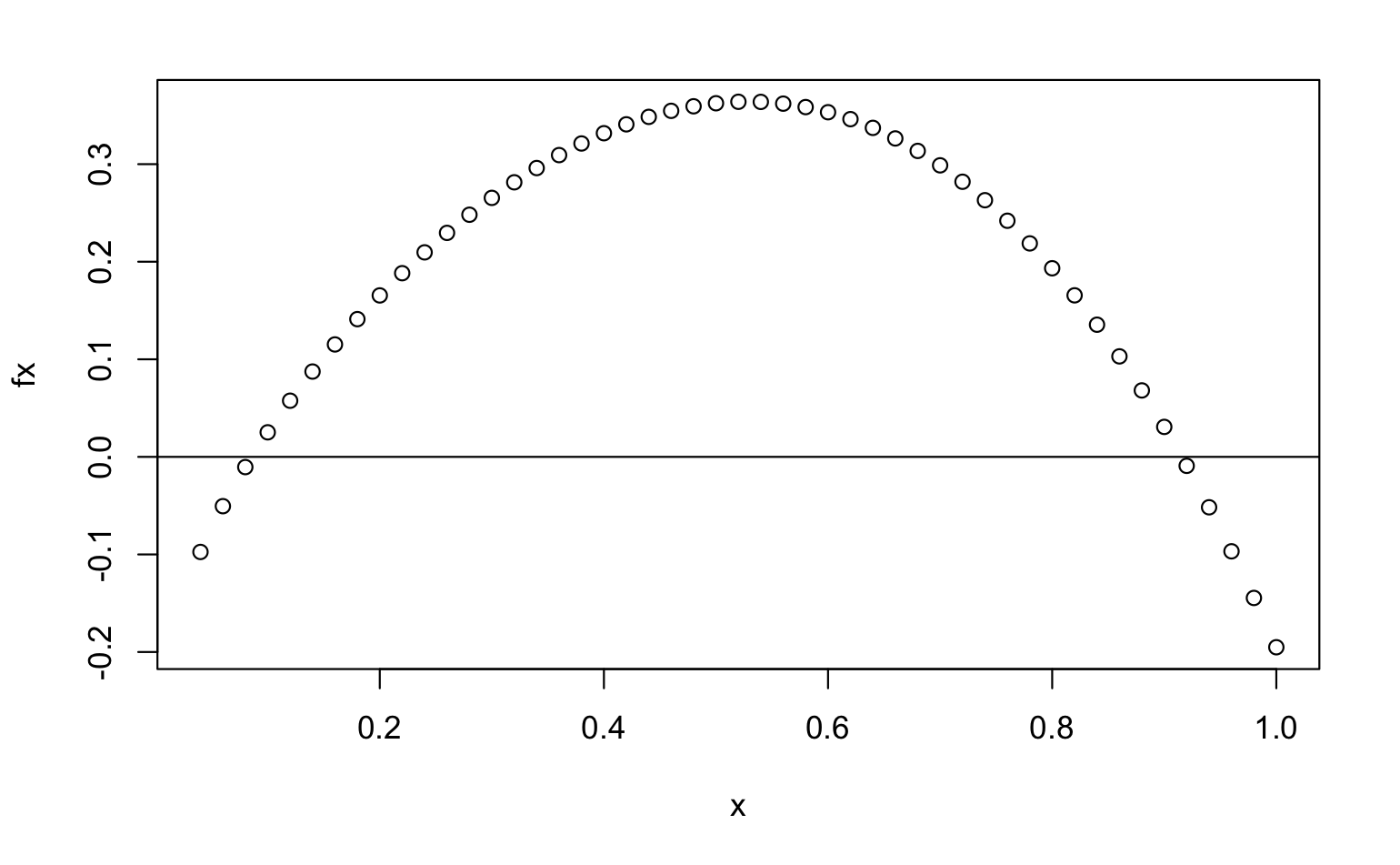
According to the Intermediate Value Theorem, the root to \(f(x)\) lies within the interval [a,b] where \(f(a)\) and \(f(b)\) have different signs (meaning one of them is positive, the other is negative). Apparently there are two roots. One lies within c(rangeX[[3]], rangeX[[4]]), the other lies within c(rangeX[[44]], rangeX[[45]]). The following code shows you the evidence of sign changes:
The task now is that given any rangeX (not necessarily the current one), you can produce a list of intervals, names list_rootSource. Each interval is recorded as a numeric vector of 2. Such that
two values from the same interval give function values of different signs, and
the second value must be the adjacent value of the first value from given rangeX. (It means that an interval can be represented as c(rangeX[[i]], rangeX[[i+1]])) for some integer i.
# list_rootSource11.5 Intermediate value theorem (IVT)
With the theorem, we know there is a root lying between 0.08 and 0.10. One way to find an approximate root is (1) to take the mean of both end points (which is (0.08+0.10)/2). If the function value of the mean is close to zero enough, we claim this mean is a good approximating root. (2) If the function value is not close to zero enough, we pick either 0.08 or 0.10 based on whose f(x) has different sign as the f(mean_value) to form a smaller root-lying interval, as a refinement procedure.
Start with root-lying interval, c(0.08, 0.10). Get a list (named refinedResult) of root, f_root, and refinedInterval, where root is the mean of the end points of root-lying interval, f_root is the function value of root, and refinedInterval is a numeric vector of root and one of the initial interval end point that meets the sign difference requirement from IVT.
startInterval <- c(0.08, 0.10)
# 取得均值
root <- {
}
# 取得均值函數值
f_root <- {
}
# 找出startInterval裡誰的f(x)與f(meanX)不同正負號
signDifferentX <- {
}
# 得到refinedInterval
refinedInterval <- c(signDifferentX, root)
refinedResult <-
list(
root=,
f_root=,
refinedInterva=
)
# refinedResult11.6 Helper functions
Based on 11.3-11.5, complete two functions get_rootCoveringInterval and get_refinedResult such that the following task would work that is: starting from given f and rangeX, ending at getting refinedResult as in (11.5).
## 任務前提
f <- f
rangeX <- rangeX
## 任務目標
refinedResult <- {
# 取得f_mapping (11.3)
f_mapping <- get_f_mapping(f, rangeX)
# 取得所有root-covering intervals (11.4)
startInterval <- get_rootCoveringInterval(f_mapping)
# 針對第一個root-covering interval, 計算它的refinedResult (11.5)
startIntervalX <- startInterval[[1]]
refinedResult <- get_refinedResult(f, startIntervalX)
refinedResult
}where you will see the outcome as:
refinedResult$root [1] 0.09
$f_root [1] 0.00780055
$refinedInterval [1] 0.08 0.09
# Put your functions definition here, but before the list
# list(
# get_rootCoveringInterval=get_rootCoveringInterval,
# get_refinedResult=get_refinedResult
# )11.7 While loop
The refinedResult in the previous question went through refinement only once. In this exercise, we want the refinedResult to be iterated many times until:
refinedResult$f_rootwhich represents approximation error has its absolute value (abs()to get the absolute value) less than errorThreshold which is default at \(10^{-10}\); andThe number of iterations can not exceed maxIt times, where maxIt is default at 500.
Use the following code chunk to guide you. You need to complete initial condition, iteration generation, and continuation flag generation for it to work.
errorThreshold <- 1e-10
maxIt <- 500
refinedResult <- {
# 取得f_mapping (11.3)
f_mapping <- get_f_mapping(f, rangeX)
# 取得所有root-covering intervals (11.4)
startInterval <- get_rootCoveringInterval(f_mapping)
# 針對第一個root-covering interval, 計算它的refinedResult (11.5)
startIntervalX <- startInterval[[1]]
# initial condition
while(flag)
{
# iterate generation
refinedResult <- get_refinedResult(f, startIntervalX)
startIntervalX <- refinedResult$refinedInterval # this one is for next iteration to work on a newly produced interval
# continuation flag generation
}
refinedResult
}11.8 Find root function
Develop a function called find_root so that given a function f, a range rangeX to search for root, and an acceptable approximating error errorThreshold with default equal to \(10^-10\). It will go through root interval refinement procedure iteratively until the absolute value of f_root (abs(-3) will give you 3) is less than errorThreshold. Then the procedure stops and returns the final refinedResult list of 3. (It is possible that there are multiple roots in range of X, your function is required to return ONLY ONE root outcome. Of course, if your function is more general to deal with multiple solutions, it is even better and welcome.)
Input arguments:
f: a function class object allowing one numerical argument.
rangeX: a numerical vector of 2, defining where to find root. For example, if
rangeX=c(1,3), the function will find root only within [1,3] intervalerrorThreshold: a number, default at \(10^{-10}\)
maxIt: a number, default at 500.
Returned value is a list of three having the same structure as refinedResult in the previous question. However, if no root is found after 500 iterations (defined by maxIt argument), return “No root is found.”
You can use the helper functions you developed in 11.6.
find_root <- function(f, rangeX, errorThreshold=1e-10, maxIt=500){
}
# find_root12. Subscripts
Subscripts are commonly used in mathematical expressions like \(x_{ij}\). Subscripts work in two (or the mixture of two) aspects. One is from dimension aspect, the other is from covariate column (相關特徵變數欄位) aspect.
12.1 Dimension aspect
In matrix, say \(x_{ij}\), the first subscript usually means “which row” and the second subscript usually means “which column”. Hence, subscript \(ij\) means from the i-th row and j-th column. A matrix of n rows and n columns can be generated via:
set.seed(5928)
n <- sample(3:7, 1)
sampleMatrix <- matrix(sample(1:100, n^2), n, n)
sampleMatrix [,1] [,2] [,3] [,4] [,5] [,6] [,7]
[1,] 71 63 1 52 60 19 96
[2,] 16 13 73 41 27 90 66
[3,] 67 14 78 37 59 70 43
[4,] 31 68 4 24 75 91 84
[5,] 12 17 85 42 83 21 98
[6,] 49 10 2 53 38 15 7
[7,] 99 54 87 74 50 55 69In this example, \(x_{4,3}\) can be retrieved through sampleMatrix[4,3] (which is 4).
Use for-loop to obtain the diagonal elements \(x_{ii}\) for i=1, …, n, and save them in diagX. You can use the following template to approach the question.
# 任務前提
n <- dim(sampleMatrix)[[1]]
diagX <- vector("numeric", n)
# 任務目標: 縮小任務,只一個i值,
i <- 1
diagX[[i]] <-
# diagX12.2 Lower triangular dimension
For a square matrix as sampleMatrix, sometimes we need to extract only its lower triangular elements. That is all the \(x_{ij}\) with \(j\leq i\). Given that each row \(i\), the number of elements having \(j\leq i\) is different, to save all the lower triangular elements list is a good storage object. Save all the lower triangular element values of sampleMatrix in lowerTriX list. You can use the following template to start with:
# 任務前提
n <- dim(sampleMatrix)[[1]]
# 任務目標(縮小版): i <- 3,找出所有x_{3j}, where j <= 3
i <- 3
lowerTriX <- vector("list", n)
lowerTriX[[i]] <-
{
# 任務前提: 給定前面的i
# 任務目標: 找出所有比i小的j所對應的sampleMatrix[i,j]值
}
# lowerTriX# 任務前提
n <- dim(sampleMatrix)[[1]]
# 任務目標(縮小版): i <- 3,找出所有x_{3j}, where j <= 3
lowerTriX <- vector("list", n)
for(i in 1:n){
lowerTriX[[i]] <- vector("numeric", i)
for(j in 1:i)
{
lowerTriX[[i]][[j]] <- sampleMatrix[i,j]
}
}
lowerTriX12.3 Covariate columns
The following code generates a sample dataframe, tracing district income over three years (districts are denoted as A, B, C; three years are 1990, 1995, 2000):
simData <- data.frame(
district=rep(LETTERS[1:3], each=3),
year=rep(seq(1990, 2000, by=5), 3)
)
simData$income <- {
sample(2000:10000, 3) -> .i
unlist(purrr::map(.i,
~{
.x+sample(-500:500,3)
}))
}
simData district year income
1 A 1990 9762
2 A 1995 8979
3 A 2000 9387
4 B 1990 4494
5 B 1995 3610
6 B 2000 4334
7 C 1990 8815
8 C 1995 8793
9 C 2000 9435When each row comes from the same identity as a stretch of descriptions to this identity, they are related within a given row. Data columns with this meaning are called covariate columns, or simply covariates.
Correspond to the data frame, researcher probably will use \(income_{ij}\) to denote income value from income column, and subscripts i, j mean the values from two different covariates. Usually it will be explained as income from district i and year j. In this term, \(income_{ij}\) subscript pair (i,j) means district value is i and year value is j. For example, \(income_{A,1995}\) means the value of income whose covariate value from district is “A” and from year is 1995. It can be retrieved in R via:
simData$income[
which(simData$district=="A" & simData$year==1995)
]Compute mean income (average across three years) of every district using for-loop and save them in meanIncomes. You may adopt the following template:
# 任務前題
districtSet <- unique(simData$district)
meanIncomes <- vector("numeric", length(districtSet))
# 任務目標(縮小版):找出districtSet[[1]]的(三年)平均所得
.x <- 1
meanIncomes[[.x]] <-
# meanIncomes# 任務前題
districtSet <- unique(simData$district)
meanIncomes <- vector("numeric", length(districtSet))
# 任務目標(縮小版):找出districtSet[[1]]的(三年)平均所得
for(.x in 1:3)
{
meanIncomes[[.x]] <- mean(simData$income[
which(simData$district==districtSet[[.x]])
])
}
meanIncomesAre you aware that all matrix dimensional-aspect subscripts can be represented as a data frame with three columns, named row, column and X, to form covariate-aspect subscripts? Can you find out how to covert a matrix into its covariate-aspect data frame. You probably would think of using as.data.frame. Unfortunately, that’s not right.
13. Loop practices
13.1 Three errors
while loop is commonly used for password input. Given the realPassword, design a programming flow such that
- When userInput does not match realPassword, it will message “The password is wrong.” and go back to ask user to input again.
- When three errors are made, message that “You have input wrongly 3 times!”, and exit the re-input loop.
- When userInput matches realPassword, message “Password correct.”
## 任務前提
realPassword <- "2ofe83"
## 一次性任務目標: 接受(flag_continuation為F) 或不接受userInput(flag_continuation為T)
.x <- 0
flag_continuation <- T
while(flag_continuation)
{
# iterate generation
# for each iterate, you iteration block
{
userInput <-
readline("Please input your password ")
}
# continuation flag generation (update)
}13.2 Password setup
When we setup a new account, password setsup is a common step that comes with style restrictions. In this exercise, we need a password to contain:
6-10 characters. If violate, message “password should contain 6-10 characters”
One of them must be a number, one of them must be a letter in small case (小寫英文字母), one of them must be a letter in capital (大寫英文字母). If violate , message “Need at least one number”, “Need at least one small case letter”, or “Need at least one capital letter” depending on the situation of violations.
Make sure the violation messages contain all the information that a user needs to know about his/her mistake. For example, an input “2nb4” will show
password should contain 6-10 characters
Need at least one capital letterHint: try message("How are you?\n", "Fine, thank you.") as well as message(c("How are you?\n", "Fine, thank you."))
A maximal number of iteration should be set at 5.
.x <- 0
flag_continuation <- T
maxIt <- 5
while(flag_continuation && .x <= maxIt)
{
# iterate generation
# iteration block
{
userInput <- readline("Input your password ")
}
# continuation flag update (generation)
}14. Reduction algorithm
Sometimes we are given a vector of many element values to compute single-value result. This is called reduction algorithm. An example is
\[\sum_{i=1,...,N} x_i,\] where \(x_i\) are from the following dataX object. Subscript \(i\) can be any number from dataX$i. For \(x_i\), say \(x_5\) it means the dataX$x value whose corresponding dataX$i value is 5; therefore, \(x_5=14\) \(x\) means from x column; subscript \(i\) means the corresponding :
set.seed(92783)
seqX <- sample(10:50,8)
dataX <- data.frame(
i=seq_along(seqX),
x=seqX
)
dataXA summation algorithm is a reduction algorithm which can be done via iteration, like:
result <- 0
for(.x in seq_along(seqX))
{
result <- result+ seqX[[.x]]
}
resultReduction algorithm usually involve with an initial value (which is result <- 0 here) to take in the impact from each element value (which is \(x_i\) here) sequentially. Other than initial value, recursive object value assignment (an object whose value depends on its current value, like reuslt <- result + seqX[[.x]] here) is a common trick.
In purrr, there is a reduce function to facilitate the computation:
seq_ini_x <- c(result=0, seqX)
purrr::reduce(
seq_ini_x,
function(result, x){
result <- result+x
}
)14.1 while
for loop could be mimicked by a while loop by completing the following three missing part marked by # (i.e. initial condition, iterate generation, continuation flag generation), please complete the following while loop:
14.2 Double summation
\[\sum_{i=1,\dots,N}\sum_{j=1,\dots, M} x_{ij}\]
15. Accumulation algorithm
Sometimes we need to track a series of outcomes that is influenced by initial condition as well as new information arrived in each period. This will require accumulation algorithm.
Coin dropping.

One coin was dropped from the top against a wall. The wall is full of nails spreading out like a grid with fixed widths and heights. A coin is dropped from positions where vertically there are nails down below, one of which it will definitely hit. When a coin hits a nail it has 0.5 chance to bounce to the left and 0.5 chance to bounce to the right. We want to simulate where the coin will land when it hits the ground.
16. Stochastic process
16.1 Random walk
A drunk man each time randomly walks to the left by one step with probability 0.5 and to the right by one step with probability 0.5. After 100 steps, what is the chance that he is off a straight line by more than 30 steps.
In mathematically, let the man start at \((x_0=0, y_0=0)\), where \((x_t, y_t)\) is the location of this man after t steps . Suppose he wants to walk alone \(y=0\) line forward. Each step \(x\) increased by 1, that is: \[x_t=x_{t-1}+1.\] So for the first step, he will end up with \(x_1=1\) which comes from \(x_1=x_0+1\). However, each step he has 0.5 chance to land on \(y_t=y_{t-1}+1\) and 0.5 change to land on \(y_t=y_{t-1}-1\). So for the first step, he has 0.5 chance to land on \(y_1=1\) which comes from \(y_1=y_0+1\), and 0.5 chance to land on \(y_1=-1\) which comes from \(y_1=y_0-1\)
but he has 0.5 chance to land on y
17. Integration
Given a function \(f(x)\), we sometimes want to find out its area for \(x\in [a,b]\) and \(f(x)>0\)
When we draw a line on an X-Y plane, the trajectory \((x,y)\) sometimes can be
Given a function \(f(x)\), we can trace a trajectory of \((x,y)\) on the x-y plane where \(y=f(x)\)
18. limit
\[\sum_{i=1,...,n} x_i=x_1+x_2+\dots+x_n\]
In mathematics, we think of questions like, “when \(x\) value approaches \(0\) will \(f(x)\) still get close to a constant value?” Mathematically, it is written as
\[\lim_{x\rightarrow 0}\ f(x)\ \mbox{exists,}\] where \(\lim_{x\rightarrow 0}\) means for any sequence denoted as \({x_1, x_2,... ,x_n,... }\) with the property that when \(i\) gets larger \(x_i\) gets as closer to 0 as possible.