Chapter 4 Choice set
library(reticulate)
use_condaenv("r-reticulate")
library(econR) # 經濟模型程式設計專題用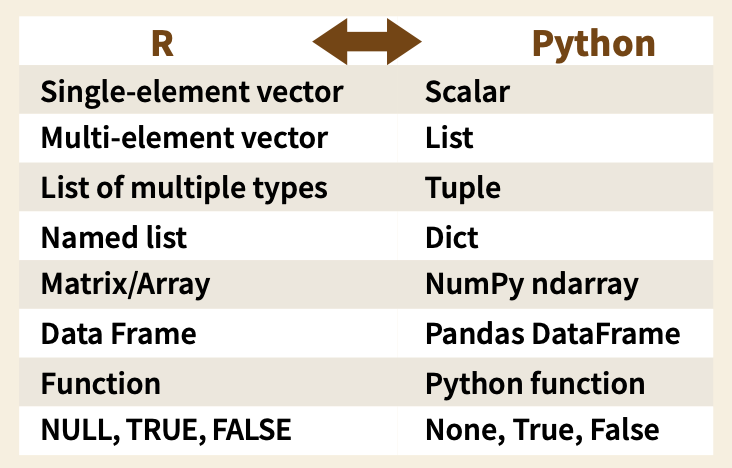
Decision Maker Problem

We need a storage object that can
represent the choice set X, with
its each element x a possible alternative for DM
In the following exercise, we want to construct object X with each element representing one x.
4.1 pRython major features
There are some major differences to notice for your first time amphibian experience:
Only
=is used for object-value binding; Python doesn’t take<-.Only
[.]is used for element VALUE extraction and replacement in Python, which is equivalent to R’s[[.]].Python element index starts from 0 instead of 1 in R
Object naming rule is the same as R, EXCEPT NO use of
.
obj_R = c("Hello", "World.")
obj_R[1]
obj_R[1] = "Hi"
print(obj_R)obj_py = ["Hello", "World."]
obj_py[0]
obj_py[0] = "Hi"
print(obj_py)obj_R2 = list(
first_word="Hello",
second_word="World"
)
obj_R2[["first_word"]]obj_py2 = {
"first_word": "Hello",
"second_word": "World"
}R’s
[[.]]extraction is equivalent to[.]in Python.R’s
[.]in list (which is the same as dictionary in Python) is equivalent to conduct (loop) comprehension (a mini-loop operation inside vector setup such as list/dictionary) operation in Python.
\[X=\{\mbox{1 apple}, \mbox{1 banana}\}\]
choiceSet_basic0 =
c(apple=1, banana=1)
# one alternative
choiceSet_basic0[1]
# the other alternative
choiceSet_basic0[2]choiceSet_basic1 =
list(apple=1, banana=1)
# one alternative
choiceSet_basic1[1]
# the other alternative
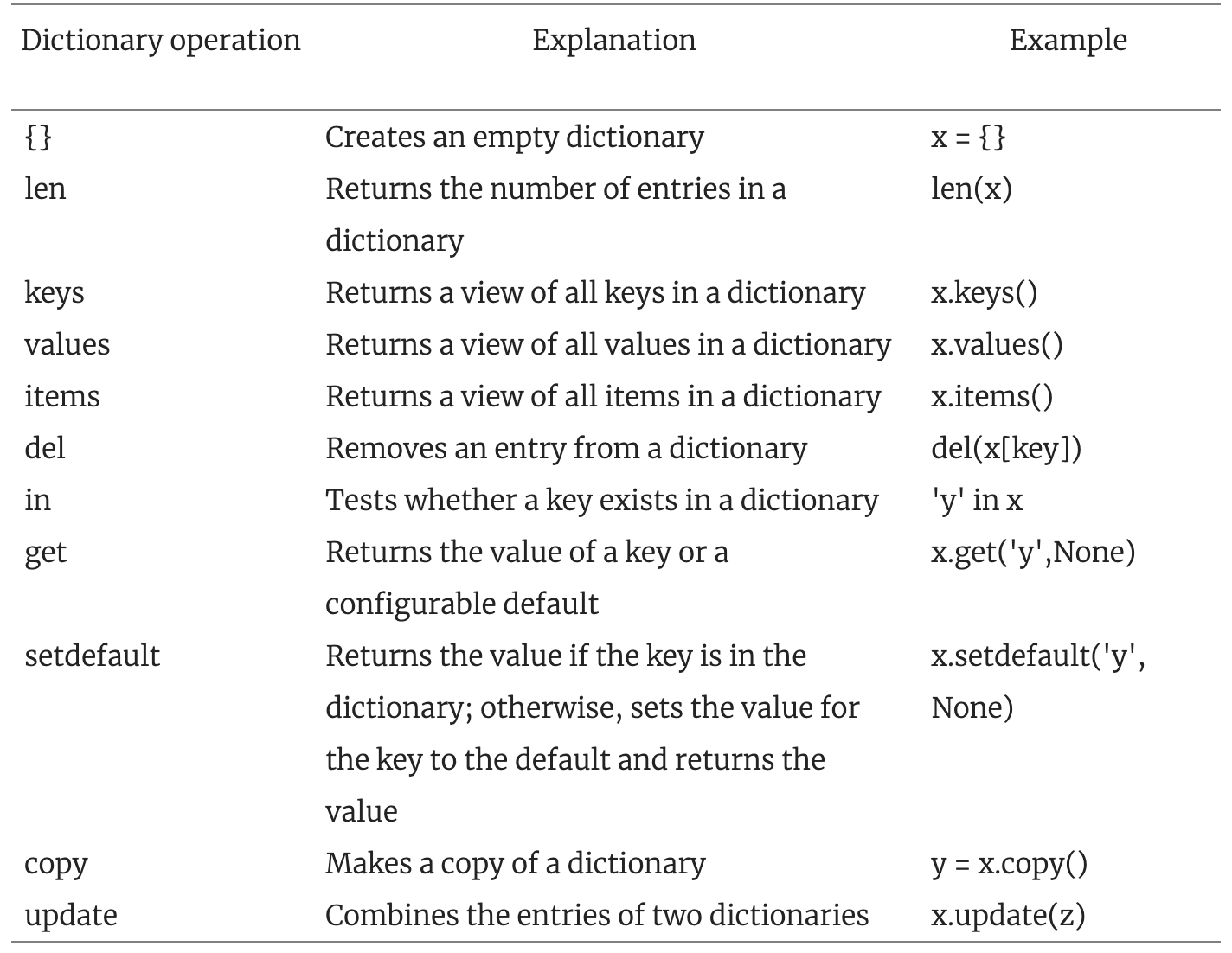
choiceSet_basic1[2]4.2 Dictionary
dict({ })
- The ONLY type of storage that allows users to give element name, called key.
choiceSet_basic0 = {"apple": 1, "banana": 1}dictionary element CANNOT be checked out by its location:
- elements are not indexed even we input them one-by-one.
# one alternative
choiceSet_basic0[0]
# the other alternative
choiceSet_basic0[1]choiceSet_basic0["apple"]
choiceSet_basic0["banana"]Python has only
[.]extraction operator, but no[[.]]or$.What
.can be depends on the type of the object.A Dictionary’s element value can be checked out only via its element key but not on its element position (you check the meaning of a word in a dictionary via the spelling of the word, not the sequence of the word entry.)
However, dictionary key can be numeric.
choiceSet_basic0_numKey = {
1: {"apple": 1},
2: {"banana": 1}
}Notice we also make index counting starting from 1 instead of 0 – another way to make it behave like R. (not useful though.)
dictionary can nest inside a dictionary
In fact, all vector types in Python:
allow element values of different types
allow nested structure,
which behaves like R: list.
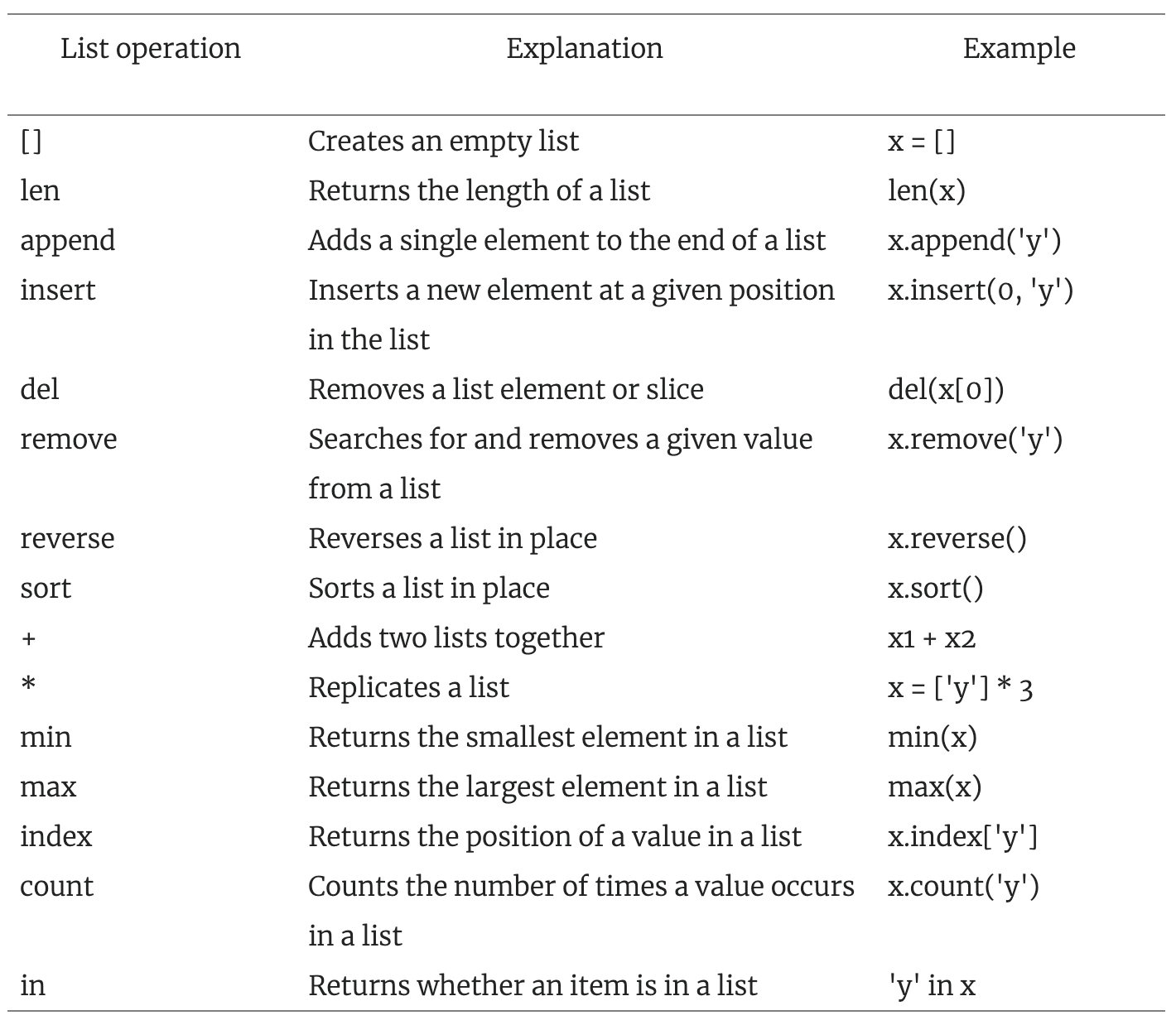
4.3 List
list([ ])
list([])list elements are indexed, but never named:
choiceSet_basic2_error = ["apple"=1, "banana"=1]choiceSet_basic2_error = ["apple": 1, "banana": 1]choiceSet_basic2 =
[{"apple": 1}, {"banana": 1}]list to give the ability of position indexation.
dictionary to give the ability of assigning element key.
4.4 Mutable v.s. Immutable
X = c(3, 53)
Y = X
pryr::address(X)
pryr::address(Y)value c(3, 53) is stored at some memory address. Object X holds the memory address like holding the key to the value storage place. The relationship of an object holding the memory address to certain data storage place is called binding.
Both X and Y hold the same address reference.
If we change X[[1]] value, will Y[[1]] change?
X[[1]] = 44
pryr::address(X)- No.
Y[[1]]will not be changed since X holds a different address reference now.
Almost all R objects are immutable; unable to change its element value in place.
In R, changing part of the object element value, in almost all cases, changes the address reference of the object – a whole new storage place is located and a new binding is formed. There is no change-in-place happening: the process is like copy old value c(3, 53) and change its first value 3 to 44, then find a new place to store c(44, 53), and give X the new place address reference.
An object stores its value under certain memory address. If that value can be changed without relocating to another memory address (i.e. value changed in place), then the object is mutable.

X = [3, 53]
Y = X
id(X)
id(Y)X[0] = 44
id(X)
print(X)
print(Y) # Y因X改變也跟著改了。To duplicate a mutable object, use .copy() method to obtain a shallow copy. This will break the link between the duplicate and the original objects.
X = [3, 53]
Y = X.copy()
id(X)
id(Y)X[0] = 44
print(X)
print(Y)X = {"banana": 1, "apple": 3}
Y = X.copy()
X["banana"]=0
print(X)
print(Y)4.5 Define Function
\[u = \mbox{number_of_banana} * 5 + \mbox{number_of_apple}*3\]
X = list(
list(
banana=0, apple=1
),
list(
banana=1, apple=0
)
)Prototyping:
x = X[[1]]
u = {
x$banana *5 + x$apple *3
}U = function(x){
assertthat::assert_that(
x %in% X,
msg="x should be an element in choice set X"
)
u = {
x$banana *5 + x$apple *3
}
return(u)
}However, %in% only works on atomic vector, not on R list. You can use:
library(magrittr)
X %>% purrr::has_element(x)library(magrittr)
U = function(x){
assertthat::assert_that(
X %>% purrr::has_element(x),
msg="x should be an element in choice set X"
)
u = {
x$banana *5 + x$apple *3
}
return(u)
}X = [
{"banana": 1, "apple": 0},
{"banana": 0, "apple": 1}
]prototyping:
x = X[0]
u = x.get("banana") * 5 + x.get("apple") *3def U(x):
assert x in X, "x should be an element in choice set X"
u = x.get("banana") * 5 + x.get("apple") *3
return u4.6 Indentation
A = 3
if(A < 5){
print("I am small.")
} else {
print("I am large.")
}A = 3
if A < 5:
print("I am small.")
else:
print("I am large.")python: indentationis equivalent toR: { }programming block.All commands belong to the same level of programming block must start with the same indentation space.
Most Python programmer uses a multiple of FOUR spaces (i.e. two tabs) to define the coverage of programming block. (two spaces, or one tab, are saved to long commands that are better read when broken into separate lines.)
A = 300
if A < 5:
print("I am small.") # Four spaces
else:
print("I am large.") # Four spaces
if A > 50:
print( # Eight spaces
"I am more than 50.") # TEN spaces (two for line breaking)Exercise 4.1 Re-write the above codes in R to show your understanding of indentation.
In a language using indentation for block programming, it is a good practice:
- ALWAYS start a NEWLINE with proper indentation at the ULTIMATE END of a programming block – this is especially important for the ending of a first level block which should end with a new line without identation.
BAD:
A = 300
if A < 5:
print("I am small.")
else:
print("I am large.")
if A > 50:
print(
"I am more than 50.") GOOD:
A = 300
if A < 5:
print("I am small.")
else:
print("I am large.")
if A > 50:
print(
"I am more than 50.")
# start a newline to end the 1st level blockExercise 4.2 Which one of the following will raise an error message? (In R, we need } else to let computer know the control flow has an else-block following. In Python, it’s proper indentation that informs computer such a thing.)
A = 3
if A < 5:
print("I am small.")
else:
print("I am large.")
if A > 50:
print(
"I am more than 50.")
# start a newline to end the 1st level blockA = 3
if A < 5:
print("I am small.")
else:
print("I am large.")
if A > 50:
print(
"I am more than 50.")
# start a newline to end the 1st level blockThe visual structure of the code reflects its real structure. This makes it easy to grasp the skeleton of code just by looking at it.
Python coding styles are mostly uniform. In other words, you’re unlikely to go crazy from dealing with someone’s idea of aesthetically pleasing code. Their code will look pretty much like yours. — Quick Python Book, Mannings.
4.7 Comparison
Relational operator python: in is equivalent to R: %in% (for atomic vectors). As to negation,
x %in% X
!(x %in% X)x in X
x not in XOther relational operator that need more attention is:
A = c(9, 10)
B = c(9, 10)
pryr::address(A)
pryr::address(B) # has different memory address
A == B # elementwise comparison
A != B
identical(A, B) # object comparision
!identical(A,B)- R only compare its class and elements, not care about its memory reference
A = [9, 10]
B = A.copy()
id(A)
id(B)
A == B # object comparison in element values
A != B
A is B # object comparison in memory address (same address definitely same content)
A is not BYou can also use:
u = x["banana"] * 5 + x["apple"] *3dict.get() not only gets value from x but also can set value when key is not available:
u = x.get("banana") *5 + x.get("apple") *3 + x.get("orange")u = x.get("banana") *5 + x.get("apple") *3 + x.get("orange", 0)
print(u)U(X[0])Economists model choice set in a continuous space often such as:
\[P_x*x + P_y*y \leq I\], where, say, \(P_x=10, P_y=25, I=10000\) In this situation, DM (decision maker) chooses \((x,y)\) that fits the restriction; his choice set can be phrased as:
\[\textbf{C}=\{(x,y) : 10x+25y\leq 10000\}\] (Usually there are restrictions of \(x, y \geq 0\) as well. At the moment, for simplicity we ignore that.)
For computer to pick up the above choice set, we can design a validation function which:
- check if \(c\) falls in \(\textbf{c}\); if yes, it returns \(c\). Otherwise, return missing value.
library(magrittr) # in order to use %>% operand
validate_c = function(c){
assertthat::assert_that(
is(c, "list") &&
c %>% purrr::every(is.numeric) &&
length(c)==2,
msg = "Only numeric vector of length 2 is possible to sit inside the choice set."
)
if(
10*c$x + 25*c$y <= 10000
){
return(c)
} else {
return(NA)
}
}c1 <- list(x=10, y=20)
validate_c(c1)
c2 <- list(x=500, y=10000)
validate_c(c2)
c3 <- c(x=50, y=10)
try(validate_c(c3)) # 確保有error也不中斷script執行For Python:
4.7.1 check type
If you aren’t familiar with Python types yet, initiate a type that you want to check:
dict0 = dict({})
dict0.__class__- It shows
dictis the verbatim (語法) that Python symbols dictionary type.
c1 = {"x": 10, "y": 20}
type(c1) is dict- Use
type(X) is type_verbatimto check if X is an object of typetype_verbatim
dict0 = dict({})
dict0.__class__
type(dict0) is dictBoolean operations:
TRUE & FALSE
TRUE && TRUE
TRUE | FALSE
TRUE || FALSETrue and True
True or FalseExercise:
dict1 = {"a": 5, "b": 0.7}Check
if
dict1["a"]anddict1["b"]are both numeric type.dict1["a"]is not a string type.
When a condition is involved of multiple relational operations:
A = 15
# condition: is numeric
type(A) is int or type(A) is floatto form a flag with other conditions, each condition is better bounded by ( ) to avoid erroneous interpretation.
A = 15
# condition1: is numeric
type(A) is int or type(A) is float
# condition2: larger than 7
A > 7A = 15
# flag True: A is a number larger than 7
(
type(A) is int or type(A) is float
) and A > 7If there is no ( ) to separate multiple conditional flags, Python deals with and first, then or:
False or True and False # return False, since it is equivalent to
False or (True and False)
True or False and False # return True, since it is equivalent to
True or (False and False)
# If you mean (A or B) and C
(False or True) and Falseprototyping:
type(c1) is dict
is_numeric(c1["x"]) and is_numeric(c1["y"])
len(c1) == 2In Python, there are only integer and float (non-integer) types. To check whether an object value is numeric, you need to either check both integer and float:
num0 = 5.5
type(num0) is int or type(num0) is floator define an is_numeric function:
def is_numeric(x):
return type(x) is int or type(x) is float
is_numeric(num0)def validate_c(c):
assert (
type(c) is dict and
is_numeric(c["x"]) and is_numeric(c["y"]) and
len(c) == 2
), "Only dictionary of length 2 is possible to sit inside the choice set."
if 10*c["x"] + 25*c["y"] <= 10000:
return c
else:
return None
# EOFWhen dealing with long operations, you can use ( ) to block the entire expression, inside ( ) you are allowed to break line before or after the operand.
Python does not give you as much coding style freedom as R:
c1 = {"x": 10, "y": 20}
c = validate_c(c1)
print(c)
c2 = {"x": 500, "y": 10000}
c = validate_c(c2)
print(c)
c is None # check if missing data
c3 = [50, 10]
try:
c = validate_c(c3)
except:
None # what to do when Error
# EOF4.8 Loops
c = {"x": 10, "y": 20}
type(c["x"]) is int and type(c["y"]) is inttype(c) is int- Won’t work.
c = [10, 20]
type(c) is intWon’t work.
Almost all basic operands in Python can not work on vectors (such as list, dictionary) directly, not like R:
c = c(10, 20)
is.numeric(c)This is because in computer language basic operands are designed for atomic objects only.
Atom, defined as the smallest storage concept in a programming language, is vector in R, but is one single value in Python.
In R, the following are atoms:
"Hi"
c("Hi","How Are You")
c(187, 192)
TRUE
c(TRUE, FALSE)- Be careful,
R: listis atom only if the element values are of the same type. If not, some coercion of type change will happen which can lead to errors or warnings.
numVec0 <- 15
numVec0 > 13
numVec1 <- c(10, 20, 0, 15)
numVec1 > 13numList1 <- list(10, 20, 0, 15)
numList1 > 13
numList1 <- list(10, "a", FALSE, 15)
numList1 > 13In Python, the following are atoms:
"Hi"
"How Are You"
187
192
True
FalsenumVec0 = 15
numVec0 > 13 # OK
numVec1 = [10, 20, 0, 15]
numVec1 > 13 # NOT OKWhen working on non-atoms, loops are required.
Prototyping via R:
numVec1 = c(10, 20, 0, 15)
lgl1 = vector("logical", length(numVec1))
for(i in seq_along(numVec1)){
lgl1[[i]] <- numVec1[[i]] > 13
}
lgl1numVec1 = [10, 20, 0, 15]
lgl1 = [False] * len(numVec1) # create a list of 4 False
for i in range(len(numVec1)):
lgl1[i] = numVec1[i] > 13
print(lgl1)4.8.1 Comprehension: mini-loop
Since Python users must deal with loops over elements inside list and dictionary often, Python equips users with a mini-loop verbatim called list comprehension and dictionary comprehension:
- When for loop result is to be saved as a list or dictionary, comprehension allows users to embed for loop inside list or dictionary to produce the result under the hood.
4.8.2 list comprehension
list comprehension:
lgl1 = ... # list type storage
for i in iterate_generator:
lgl1[i] = iteration command that generates i-th resultlgl1 = [ iteration command that generates i-th result
for i in iterate_generator]numVec1 = [10, 20, 0, 15]
lgl1 = [False] * len(numVec1) # create a list of 4 False
for i in range(len(numVec1)):
lgl1[i] = numVec1[i] > 13
print(lgl1)- No need to initiate a storage object. Just keep the iteration part:
for i in range(len(numVec1)):
lgl1[i] = numVec1[i] > 13Corresponding list comprehension:
lgl1 = [ numVec1[i] > 13 for i in range(len(numVec1))]4.8.3 Loop over dictionary:
numDict1 = {"a": 15, "b": 20, "c": 0, "d": 15}
keys = list(numDict1.keys())
dict1 = dict({}) # initiate dict storage
for i in range(len(numDict1)):
dict1.update(
{ keys[i]: numDict1[keys[i]] > 13}
)
print(dict1)dict.keys()generates keys of dict object.
numDict1 = {"a": 15, "b": 20, "c": 0, "d": 15}
dict1 = dict({}) # initiate dict storage
for (key_i, value_i) in numDict1.items():
dict1.update({
key_i : value_i > 13 })
print(dict1)dict.items()generates (key, value) pair.
4.8.4 dictionary comprehension
Dictionary comprehension
dict1 = dict({}) # dict type storage
for i in iterate_generator:
key_i = iteration command that generates i-th key # key_i expression
dict1.update({key_i: iteration command that generates i-th value})dict1 = {
key_i expression : iteration command that generates i-th value
for i in iterate_generator }numDict1 = {"a": 15, "b": 20, "c": 0, "d": 15}
keys = list(numDict1.keys())
dict1 = dict({}) # initiate dict storage
for i in range(len(numDict1)):
dict1.update(
{ keys[i]: numDict1[keys[i]] > 13}
)
print(dict1)- Focus only on iteration part:
for i in range(len(numDict1)):
dict1.update(
{ keys[i]: numDict1[keys[i]] > 13}
)- Dictionary comprehension:
numDict1 = {"a": 15, "b": 20, "c": 0, "d": 15}
keys = list(numDict1.keys())
dict1 = {
keys[i]: numDict1[keys[i]] > 13 for i in range(len(numDict1))
}
print(dict1)Dictionary is also equipped with another possible iteration:
dict1 = dict({})
for key_i, value_i in numDict1.items():
dict1.update(
{key_i: value_i > 13}
)
print(dict1)dict.items()generate (key_i, value_i) pairsFocus on iteration part:
for key_i, value_i in numDict1.items():
dict1.update(
{key_i: value_i > 13}
)- dictionary comprehension:
numDict1 = {"a": 15, "b": 20, "c": 0, "d": 15}
dict1 = {
key_i: value_i > 13 for key_i, value_i in numDict1.items()
}
print(dict1)4.8.5 Python loop efficiency
Python loop efficiency starts from its iterate generator, which acts like a function that produces iterate only when needed – no vector of iterates that occupied memory in advance.
# iterable
numDict1.keys() # iterate generator: any object that can make iteration happen -- iterable
# collection of iterates
list(numDict1.keys()) # show you what iterates can it generate as a list
# iterator
iter_numDict1Keys = iter(numDict1.keys()) # produce an iterator
next(iter_numDict1Keys)
next(iter_numDict1Keys)
next(iter_numDict1Keys)
next(iter_numDict1Keys)- In R, loops requires collection of iterates which take away memory space.
Several iterables:
- range:
range(len(object))for k in range(len(object)):
...For dictionary object, the following are common iterables:
for k in numDict.keys():
...for k, v in numDict.items():
...4.9 Help
Python uses class.method, or namespace.function to check out the help menu.
help(objectType.method)dict0 = {"apple":2, "banana":3}
dict0.__class__
help(dict.clear) # class.method
help(dict.fromkeys)import math
help(math.acos) # namespace.functionBuiltin functions can be checked directly:
help(range)4.10 綜合練習
1. Foodpanda Sukiya
1.1
# newPromotion1
allLevels =
c(
"新登場",
"推薦套餐",
"豪華雙饗丼",
"牛丼類",
"咖哩類",
"豬肉丼類")
newPromotion1 <- list(
"category" = "新登場",
"item" = "番茄牛丼",
"description"= "新鮮番茄的酸味,讓人食慾大開!",
"price" = 109
)
# newPromotion1 1.2
recommend1 <- list(
"category" = "推薦套餐",
"item" = "蔥溫玉牛丼套餐",
"description"= "蔥溫玉牛丼+自選套餐",
"price" = 149
)
# recommend11.3
sukiyaMenu <- list(
newPromotion1,
recommend1
)
# sukiyaMenu1.4
sukiyaMenu2 <- sukiyaMenu
sukiyaMenu2[[1]]$category <-
factor(c("牛丼類"), levels=allLevels)
sukiyaMenu2[[1]]$price <- 120
# sukiyaMenu21.5
sukiyaMenu3 <- purrr::transpose(sukiyaMenu)
sukiyaMenu3$category <- unlist(sukiyaMenu3$category)
sukiyaMenu3$item <- unlist(sukiyaMenu3$item)
sukiyaMenu3$description <- unlist(sukiyaMenu3$description)
sukiyaMenu3$price <- unlist(sukiyaMenu3$price)
sukiyaMenu31.6
sukiyaMenu4 <- sukiyaMenu
sukiyaMenu4[[1]][c("item","description","price")] -> options
sukiyaMenu4[[1]][c("item","description","price")] <- NULL
sukiyaMenu4[[1]]$options <- options
sukiyaMenu4[[2]][c("item","description","price")] -> options
sukiyaMenu4[[2]][c("item","description","price")] <- NULL
sukiyaMenu4[[2]]$options <- options
sukiyaMenu4
# sukiyaMenu42. Budget constraint
Consider the budget constraint:
\[\ P_{apple} * x_1 + P_{banana} * x_2 \leq I\]
Suppose \(I=1000, P_{apple}=5, P_{banana}=7\). Suppose \(x_1\) and \(x_2\) must be integer.
2.1
Suppose we decide to use [2,3] in Python to represent the alternative of 2 apples and 3 bananas. Given \(x1=3\), list all [x1, x2] alternative that satisfies the budget constraint in a list. That is your answer should look like [[3,0], [3,1], [3,2], ...] and each element is inside the choice set.
2.2
In Python, a list can append a new value or extend values such as:
list0 = [2, 3, 7]
list1 = list0.copy()
newList = [5, "b"]
list0.append(newList)
print(list0)
list1.extend(newList)
print(list1)Construct a list that contains all the [x1, x2] pair inside the budget constraint. You may need to use append or extend methods above.
3. Atoms
par0 <- c(5)
par1 <- 3
2**par0 # **: 次方
2**par1There is something wrong in the following. Fix it.
par0 = [5]
par1 = 3
2**par0
2**par1